13 ネットワークの基礎 #Edit source
| 改訂履歴 | |
|---|---|
| 2024-06-21 | |
概要#
Linux には、全ての種類のネットワーク構成で利用することのできる、様々なネットワークツールやネットワーク機能が用意されています。ネットワークカードを利用したアクセス設定は YaST で行うことができます。もちろん手作業での設定も可能です。本章では、ごく基本的な構造と、関連するネットワーク設定ファイルについて説明しています。
Linux や他の Unix オペレーティングシステムでは、 TCP/IP プロトコルを使用します。これは単一のネットワークプロトコルを指す用語ではなく、様々なサービスを提供するネットワークプロトコルファミリを指す用語です。 TCP/IP プロトコルファミリで使用される主なプロトコル に示されているプロトコルの一覧は、 TCP/IP を介して 2 台のマシン間でデータを交換するために提供されているものです。また、 TCP/IP で構成されたネットワークを世界中に広げたものを、 「インターネット」 と呼びます。
RFC とは Request for Comments の略で、インターネットプロトコルの説明やオペレーティングシステム内での実装手順のほか、応用例などを説明している文書です。言い換えると、 RFC の文書はインターネットプロトコルの構造と仕組みを説明しているものになります。 RFC についての詳細は https://datatracker.ietf.org/ (英語) をお読みください。
TCP/IP プロトコルファミリで使用される主なプロトコル #
- TCP
伝送制御プロトコル (Transmission Control Protocol) と呼ばれるプロトコルで、接続指向のプロトコルです。アプリケーションからもたらされた送信データは、一連のデータとしてオペレーティングシステム側で書式変換が行われます。宛先のホストにその変換済みのデータが到着すると、逆変換を行って元のデータに戻して、受信側のアプリケーションに配信されます。 TCP では途中のデータが喪失してしまったり、順序が入れ替わってしまったりした場合でも、それを修復して元通りの構成に戻す機能を備えています。つまり、 TCP は順序が重要となるデータを送信する際に便利な仕組みです。
- UDP
ユーザデータグラムプロトコル (User Datagram Protocol) と呼ばれるプロトコルで、接続制御のないプロトコルです。アプリケーションからもたらされた送信データは、書式変換のみを行って送信されます。受信側では逆変換を行いますが、受信側での到着順序については保証が無く、場合によってはデータを喪失してしまうこともあります。 UDP はひとかたまり (パケット) のデータを送信する際に便利なプロトコルで、 TCP よりも遅延を少なくすることができます。
- ICMP
インターネット制御メッセージプロトコル (Internet Control Message Protocol) と呼ばれるプロトコルで、エンドユーザ側で使用するプロトコルではなく、ネットワーク内でのエラー報告を行ったり、 TCP/IP データ伝送に参加している機器を制御したりするためのプロトコルです。これに加えて、 ping というプログラムを利用してネットワークの通信が成立しているかどうかを調べるプロトコルも用意されています。
- IGMP
インターネットグループ管理プロトコル (Internet Group Management Protocol) と呼ばれるプロトコルで、 IP マルチキャストと呼ばれる仕組みを実装する際、それに参加するマシンの動作を制御するためのプロトコルです。
図13.1「TCP/IP での単純化したレイヤモデル」 に示されているとおり、コンピュータ間でのデータ交換は階層 (レイヤ) 型の構造で処理されます。ネットワーク層は実際には IP (インターネットプロトコル) を介した通信で、 IP の上にトランスポート層の TCP (伝送制御プロトコル) が乗り、順序保証やある程度のセキュリティが確保されたデータ転送を実現しています。また、 IP 層はその下にあるハードウエア依存のプロトコル (例: イーサネット) 上で動作しています。

図 13.1: TCP/IP での単純化したレイヤモデル #
上の図では、各レイヤに対して 1 つもしくは 2 つの例を示しています。レイヤは 抽象レベル とも呼べる仕組みで、低いレイヤほどハードウエアに近く、高いレイヤほどハードウエアからは離れた独立した仕組みになります。また、それぞれのレイヤには、名前からおおよそ推測のできる独自の機能が用意されています。なお、データリンク層と物理層は、イーサネットなどの物理的なネットワークを表しています。
ほぼ全てのハードウエアプロトコルはパケット指向の仕組みで動作します。通常は送信すべきデータを 1 回では送信できないため、 パケット と呼ばれる単位で小分けして送信します。 TCP/IP の場合、パケットの最大サイズはおおよそ 64 KB 程度になりますが、ネットワークハードウエア側ではそれより小さい単位でしか送信できないことから、実際にはもっと小さくなります。たとえばイーサネットの場合、これは 1500 バイト程度のもので、イーサネット経由で TCP/IP パケットを送信する場合も、この単位で送信することになります。
それぞれのレイヤがその機能を提供するため、データパケット内にはそれぞれのレイヤが必要とする情報を保存しなければなりません。この情報は、パケット内では プロトコルヘッダ と呼ばれ、この中に情報を保存します。プロトコルヘッダは、名前の通り実際のデータよりも前に置かれますので、たとえばイーサネットケーブル上を通過する TCP/IP データパケットの場合は、 図13.2「TCP/IP イーサネットパケット」 で示す図のようになります。なお、チェックサム (checksum) のみが冒頭ではなく、末尾に付いています。このような仕組みにより、ネットワークハードウエアでの処理を容易にしています。
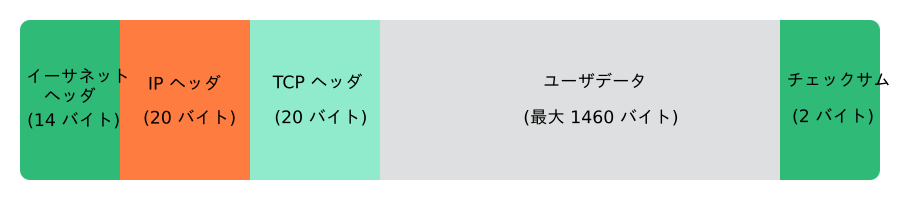
図 13.2: TCP/IP イーサネットパケット #
アプリケーションがネットワークを介してデータを送信する際、データはそれぞれのレイヤを通過します。物理レイヤを除き、全てのレイヤが Linux カーネルで実装されています。それぞれのレイヤはデータを準備して次のレイヤに送信する仕組みになっていて、最も下のレイヤがデータ送信に対する最終的な責任を負う構造になっています。データを受信した場合は、この逆順で処理が行われます。タマネギの皮のように、受信したデータからそれぞれのプロトコルヘッダを削除していって、最終的にはトランスポート層がアプリケーションにデータを提供します。このような構造により、それぞれのレイヤは隣り合ったレイヤとだけやりとりを行えば十分な仕組みになっていますので、アプリケーション側では有線なのか無線なのかを気にせずに通信できるようになっています。同様に、パケットが正しい形式に変換されている限り、データ回線側もデータの種類を気にする必要はありません。
13.1 IP アドレスとルーティング #Edit source
本章では、 IPv4 ネットワークに限定して説明しています。 IPv4 プロトコルの後継である IPv6 プロトコルについては、 13.2項 「IPv6—次世代インターネット」 をお読みください。
13.1.1 IP アドレス #Edit source
インターネットに接続されているコンピュータには、他のコンピュータと重複しない 32 ビットのアドレスが付与されています。この 32 ビット (4 バイト) は通常、 例13.1「IP アドレスの書き方」 の 2 行目のような書式で記述します。
例 13.1: IP アドレスの書き方 #
IP アドレス (バイナリ): 11000000 10101000 00000000 00010100 IP アドレス (10 進数) : 192. 168. 0. 20
10 進数の表示では、 4 バイトそれぞれを 10 進数で表し、ピリオドでそれぞれを区切ります。 IP アドレスはホストやネットワークインターフェイスに割り当てるもので、世界中を通して唯一のものでなければなりません。一部例外もありますが、本章の説明では省略します。
IP アドレスは階層構造型の仕組みで作られています。 1990 年代までは、 IP アドレスに 「クラス」 と呼ばれる分類が設定され、厳格に守られてきました。しかしながら、このような構造は柔軟性に欠けるため、現在は使用されていません。現在は クラスレスルーティング (CIDR, Classless InterDomain Routing) と呼ばれる仕組みで、クラスを使用しないようになっています。
13.1.2 ネットマスクとルーティング #Edit source
ネットマスクとは、サブネットのアドレス範囲を定義するために使用するものです。 2 つのアドレスが同じサブネット内にある場合、それらは直接通信することができます。同じサブネット内に無い場合は、そのサブネットに到達するまでの中継器 (ゲートウエイ) のアドレスを介して、通信を行う必要があります。 2 つの IP アドレスが同じサブネット内にあるかどうかを確認するには、それぞれのアドレスをネットマスクで 「論理積 (AND)」 して、結果が同じであるかどうかを調べます。結果が異なる場合、双方が通信する際にはゲートウエイを介して通信する必要があることになります。
ネットマスクの仕組みについて知るには、まず 例13.2「IP アドレスとネットマスクのつながり」 をご覧ください。ネットマスクは 32 ビットの値で、 IP アドレスのどの部分までがサブネットであるのかを示しています。サブネット側に属する部分が 1 に、それ以外の部分が 0 になっていますので、論理積 (AND) を取れば、ネットワーク部分だけを抽出できることになります。言い換えると、より小さなサブネットほど 1 の数が多いことになります。また、ネットマスクは 1 が連続して現れることから、 1 の長さでネットマスクを表すこともできます。たとえば 例13.2「IP アドレスとネットマスクのつながり」 では 24 個の 1 になっていますので、前者を 192.168.0.0/24 と記述することができます。
例 13.2: IP アドレスとネットマスクのつながり #
IP アドレス (192.168.0.20) : 11000000 10101000 00000000 00010100 ネットマスク(255.255.255.0): 11111111 11111111 11111111 00000000 --------------------------------------------------------------- 論理積の結果: 11000000 10101000 00000000 00000000 10 進数への変換結果: 192. 168. 0. 0 IP アドレス (213.95.15.200): 11010101 10111111 00001111 11001000 ネットマスク(255.255.255.0): 11111111 11111111 11111111 00000000 --------------------------------------------------------------- 論理積の結果: 11010101 10111111 00001111 00000000 10 進数への変換結果: 213. 95. 15. 0
もう 1 つの例を挙げましょう。同じ LAN 内に接続されているコンピュータの場合、それら全ては同じサブネット内に存在していて、直接アクセスすることができます。スイッチやブリッジで物理的に区切られている場合でも、これらのホスト同士は直接アクセスすることができます。
逆に、異なるサブネットの IP アドレス同士は、ゲートウエイの介在無しにはアクセスすることができません。最もよくある環境では、ゲートウエイは 1 台だけで、そのゲートウエイが全てのサブネットに対するアクセスを中継します。環境によっては、複数のゲートウエイが存在していたりすることもあります。
このように、お使いのネットワーク内にゲートウエイが存在する場合は、異なるサブネット宛の通信は全てゲートウエイを介して接続します。ゲートウエイはホスト間で通信を行うのと同じ手順で、一方から他方にデータ (パケット) を中継します。ただし、各パケットには TTL (Time To Live) という値が設定されていて、ゲートウエイを通過するごとに 1 つずつ減らされ、 0 になると廃棄されてしまいます。
様々なアドレス #
- ネットワークアドレス
このアドレスは、コンピュータの IP アドレスとネットマスクの論理積を取った結果で、 例13.2「IP アドレスとネットマスクのつながり」 の図では
論理積の結果として示しているものです。このアドレスは、コンピュータに割り当てることができません。- ブロードキャストアドレス
このアドレスは、 「そのサブネット内にある全てのホスト」 を意味するアドレスです。このアドレスを生成するには、ネットマスクの
1と0を入れ替えて、 IP アドレスとの論理和 (OR) を取った値になります。上記の例では、 192.168.0.255 となります。このアドレスも、コンピュータに割り当てることができません。- ローカルホスト
127.0.0.1というアドレスは特殊扱いのアドレスで、各ホストの 「ループバックデバイス」 に割り当てます。このアドレスを指定することで、自分自身のコンピュータにアクセスすることができるようになっています。より正確に表現すると、このアドレスは127.0.0.0/8というネットワークアドレスで、 IPv4 の規格として決められているものです。なお、 IPv6 の場合は、ループバックアドレスは 1 つだけ (::1) になっています。
IP アドレスは全世界で唯一のものでなければならないことから、適当にアドレスを割り当てて良いというものではありません。ただし、内部で使用するためだけの 「プライベート IP アドレス」 と呼ばれるアドレスがあり、インターネットには直接接続しない環境下で使用することができるようになっています。これらのアドレス帯域は RFC 1597 で規定されているもので、 表13.1「プライベート IP アドレスの範囲」 に一覧を示しています。
表 13.1: プライベート IP アドレスの範囲 #
|
ネットワーク/ネットマスク |
範囲 |
|---|---|
|
|
|
|
|
|
|
|
|
13.2 IPv6—次世代インターネット #Edit source
World Wide Web (WWW) の普及に伴い、インターネットは爆発的に拡大しています。それに伴い、過去 15 年の間に TCP/IP を介して通信するコンピュータも、爆発的な数に膨れあがってきています。 CERN ( https://public.web.cern.ch ) の Tim Berners-Lee 氏が 1990 年に WWW を発明して以降、数千台規模のインターネットホストが、今は 1 億台以上にもなってきています。
上述のとおり、 IPv4 アドレスは 32 ビットしかありません。また、ネットワークの管理上の都合から、いくつかの IP アドレスが使用できなくなってしまっています。また上述のとおり、サブネットは 2 進数で表記するため、 2 のべき乗 - 2 個 (ネットワークアドレスとブロードキャストアドレス) のアドレスしか利用できません。たとえば 128 台のコンピュータをインターネットに接続する場合、 256 個のアドレスのサブネット (実際には 256 - 2 = 254 個のアドレスが利用可能) を利用する必要があります。
なお、現在の IPv4 プロトコルには、 DHCP や NAT (ネットワークアドレス変換 (Network Address Translation)) の仕組みがあり、アドレスが枯渇する問題を回避しうる仕組みを備えています。また、上述のプライベートアドレスを併用して、それぞれを個別に管理することでも、確実に枯渇を防いでいます。なお、 IPv4 のネットワーク内でホストを構築するには、そのホストに割り当てるアドレスとサブネットマスク、ゲートウエイのアドレスとネームサーバのアドレス (必要であれば) をそれぞれ設定することになります。これら全ての設定はそれぞれ異なるものであるため、あらかじめ知っておく必要があります。
IPv6 を利用することで、アドレスの枯渇と複雑化した設定を過去のものにすることができます。下記の章では、 IPv6 で改善された内容や新しい内容を紹介しているほか、 IPv4 からの移行方法についても説明しています。
13.2.1 利点 #Edit source
IPv6 プロトコルにおいて最も重要でかつ目立つ改善点として、アドレス領域の巨大化があります。 IPv4 では 32 ビットしかなかったアドレスが、 IPv6 では 128 ビットの巨大なアドレス領域になっています。これにより、数千兆個ものアドレスを割り当てることができるようになります。
しかしながら、 IPv6 アドレスはアドレス領域を拡張しただけではありません。内部構造を新しくすることで、システムとネットワークに関する情報をより効率的に処理できるようになっています。詳しくは 13.2.2項 「アドレスの種類と構造」 をお読みください。
IPv6 プロトコルにおける利点の一覧は下記のとおりです:
- 自動設定
IPv6 ではネットワークを 「プラグ&プレイ」 対応に進化させています。これにより、新しいコンピュータを (ローカルの) ネットワークに接続する際、手作業での設定作業を全く必要としなくなっています。コンピュータを新しく接続すると、自動設定の仕組みが動作し、ルータが提供する情報をもとにして独自のアドレスを割り当てます。これは neighbor discovery (ND) プロトコルと呼ばれる仕組みです。この方法では、管理者側で行う作業は何もなく、 IPv4 で自動的なアドレス割り当てを実現していた DHCP サーバのように、アドレスを割り当てるための中央サーバも不要です。
ルータがスイッチに接続されている場合でも、ルータはネットワークに接続するための情報を定期的に発信し続けます。詳しくは RFC 2462 と
radvd.conf(5)のマニュアルページ、そして RFC 3315 をお読みください。- モビリティ
IPv6 では、 1 つのネットワークインターフェイスに対して複数のアドレスを割り当てることができます。この仕組みにより、複数のネットワークに簡単に接続することができるため、携帯電話の事業者が提供する国際ローミングのように使用することができます。たとえばお使いの携帯電話を海外に持ち出した場合、その電話機は自動的にその地域の携帯電話サービスに接続しますが、どの国でも同じ番号のまま発着信できて、国内にいる場合と全く同じ使い心地で使用することができます。これと同じような仕組みを利用することができます。
- セキュリティ
IPv4 ではネットワークセキュリティ (IPsec) がオプション扱いでしたが、 IPv6 では IPsec が中枢機能の 1 つとなり、盗聴の可能性があり得るインターネットの世界で、機密の守られた通信を行うことができるようになっています。
- 後方互換性
現実的には、インターネット全体を一気に IPv4 から IPv6 に移行することは不可能です。そのため、インターネット内だけでなく、それぞれのシステムにも両方のプロトコルを共存させる仕組みが必須となります。このような要件から、互換アドレス (IPv4 アドレスを容易に IPv6 アドレスに変換できるアドレス) が用意され、トンネルを介してアクセスできる仕組みになっています。詳しくは 13.2.3項 「IPv4 と IPv6 の共存」 をお読みください。システム側では デュアルスタック IP と呼ばれる技術により、両方のプロトコルに対応し、どちらのプロトコルを経由してもインターネットにアクセスできる構造になっています。
- マルチキャストを利用した独自サービス
IPv4 では、 SMB などのサービスでブロードキャストを利用し、ローカルネットワーク内の全てのホストにパケットを送信していました。 IPv6 では、より精密なアプローチである マルチキャスト を利用して、特定のグループ内の全体に情報を伝えることができるようになっています。これは全てのホストに通知する ブロードキャスト とも、特定の 1 台のホストのみに通信する ユニキャスト とも異なる仕組みです。どのホストがグループとして割り当てられるのかは、それぞれの用途によって異なります。あらかじめ決められたグループとしては、全てのネームサーバ (全ネームサーバマルチキャストグループ) や全てのルータ (全ルータマルチキャストグループ) などがあります。
13.2.2 アドレスの種類と構造 #Edit source
上述のとおり、現在の IP プロトコルには 2 種類の大きな制限があります。 IP アドレスの枯渇と、それに伴って発生する経路制御 (ルーティング) テーブルの複雑化、そしてその運用の煩雑さです。 IPv6 では、アドレス領域を拡張することによって前者を解決していますし、後者についてはネットワークアドレスを構造化し、より整理された管理を行うと共に、 マルチホーミング (複数のアドレスを 1 台のデバイスに設定し、複数のネットワークそれぞれにアクセスできる機能) でそれらを解決しています。
IPv6 を扱うにあたっては、まずアドレスの種類について知っておくことをお勧めします:
- ユニキャスト
この種類のアドレスは、厳密に 1 つのネットワークインターフェイスに関連づけられるものです。このアドレス宛に発信されたパケットは、特定の 1 台に宛てて送信されます。そのため、ユニキャストのアドレスは、ネットワーク内やインターネットで、特定のホスト同士が通信する際に使用します。
- マルチキャスト
この種類のアドレスは、ネットワークインターフェイスのグループに関連づけられるものです。このアドレス宛に発信されたパケットは、グループに属する全ての宛先に送信されます。マルチキャストアドレスは、主に特定のネットワークサービスが使用するもので、特定のグループに属するホストに対して通信する際に使用します。
- エニーキャスト
この種類のアドレスも、ネットワークインターフェイスのグループに関連づけられるものです。ただし、このアドレス宛に発信されたパケットは、ルーティングプロトコルの仕組みに従って、最も送信者に近いグループのメンバーに配信されます。エニーキャストアドレスは、特定のサービスを提供するサーバが、インターネット内に多数存在するような場合に利用します。同じ種類のサービスのサーバは、同じエニーキャストアドレスを持ちます。通常はルーティングプロトコルの仕組みで最も近いサーバに送信されますが、そのサーバが利用できない場合は 2 番目に近いサーバに、そのサーバも利用できない場合は 3 番目に近いサーバに、のように配信されます。
IPv6 アドレスは 4 桁のフィールド 8 個で構成されています。それぞれのフィールドは 16 ビットの値を 16 進数で表す仕組みで、フィールド間はコロン ( : ) で区切ります。また、 16 進数の上位の桁が 0 であった場合は 0 を省略して表記しますが、逆に下位の桁が 0 であった場合には省略を行いません。また、特定のフィールドが完全な 0 であった場合にはそのフィールドの表記を省略して、 :: と表します。ただし :: は 1 つしか設定できません。アドレス表記の例を 例13.3「IPv6 アドレスの例」 に示します (いずれも同じアドレスを表しています):
例 13.3: IPv6 アドレスの例 #
fe80 : 0000 : 0000 : 0000 : 0000 : 10 : 1000 : 1a4 fe80 : 0 : 0 : 0 : 0 : 10 : 1000 : 1a4 fe80 : : 10 : 1000 : 1a4
IPv6 アドレスは、パートごとにそれぞれの意味があります。最初のいくつかのバイトはプレフィクスとアドレスの種類を表します。中央の部分はアドレスのネットワークパートと呼ばれ、場合によっては使用しません。末尾の部分はホストパートと呼ばれ、特定のホストを表す部分になります。また、 IPv6 でのネットマスクはアドレスの末尾にスラッシュを置き、その後ろにプレフィクスの長さをビット数で表します。たとえば 例13.4「プレフィクス長付きの IPv6 アドレス」 のアドレスの場合は、最初の 64 ビットまでがアドレスのネットワークパートで、残りの 64 ビットがホストパートであることを示しています。これを言い換えると、 64 とは左側から 64 ビット分までがネットワークパートであることになります。 IPv4 では、論理積 (AND) を利用して同じサブネットかどうかを判断していましたが、 IPv6 ではビット数のみを使用して判断します。
例 13.4: プレフィクス長付きの IPv6 アドレス #
fe80::10:1000:1a4/64
IPv6 には、いくつかの定義済みプレフィクスが存在しています。そのうちのいくつかを IPv6 プレフィクス で示します。
IPv6 プレフィクス #
00IPv4 アドレスと IPv4 over IPv6 互換アドレスを表します。これらは IPv4 との互換性を維持するために使用されているもので、ルータが IPv6 パケットを IPv4 パケットに変換できるようにするために使用します。このほか、ループバックデバイス向けのアドレスなどもこのプレフィクスを使用しています。
- 最初の 1 桁が
2または3 集約可能なグローバルユニキャストアドレス (Aggregatable global unicast addresses) と呼ばれるものです。 IPv4 の場合と同様に、インターフェイスに対して特定のサブネットの一部を構成するために割り当てられるものです。現時点では、下記のアドレス領域が存在しています:
2001::/16(本番用アドレス領域) および2002::/16(6to4 用アドレス領域)fe80::/10リンクローカルアドレスと呼ばれ、このプレフィクスを持ったアドレスは経路制御を行うべきではなく、そのため同じサブネット内にしかアクセスできないアドレスです。
fec0::/10サイトローカルアドレスと呼ばれ、経路制御を行ってもかまわないものの、所属する特定の組織内でのみ使用すべきものです。実際には、
10.x.x.xなどの IPv6 アドレスにおけるプライベートアドレスとも呼べるものです。ffこれらはマルチキャストアドレスです。
ユニキャストアドレスには、 3 種類の基本コンポーネントが含まれています:
- パブリックトポロジ
最初の部分 (上述のプレフィクスを含む) は、一般的なインターネットを介してパケットを経路制御する際に使用します。インターネットアクセスを提供する企業や団体の情報を含む部分です。
- サイトトポロジ
2 つ目の部分には、パケットの配信先のサブネットに関する経路情報が含まれています。
- インターフェイス ID
3 つ目の部分には、パケットの配信先となるインターフェイスを識別するための情報が含まれています。このような構造により、 MAC アドレスをそのままアドレスとすることができるようになっています。 MAC アドレスが全世界で唯一の番号であると仮定すると、ハードウエアの製造元が固定の識別子をデバイスに割り当てていることになりますので、設定の手順も単純化できることになります。実際のところ、最初の 64 ビットのアドレスは
EUI-64トークンを構成する値で、最後の 48 ビットは MAC アドレスから生成し、残りの 24 ビットはトークンの種類を示す特殊な情報を設定します。また、 point-to-point protocol (PPP) ベースのインターフェイスのように、 MAC アドレスを持たないものに対しても、EUI-64トークンを割り当てることができます。
このような基本的なネットワーク構造に加えて、 IPv6 では 5 種類のユニキャストアドレスが規定されています:
::(未指定)このアドレスは、インターフェイスを起動する際に初期のアドレスとして使用するものです。
::1(ループバック)ループバックデバイスのアドレスです。
- IPv4 互換アドレス
この IPv6 アドレスは IPv4 アドレスを示すもので、 96 ビットのゼロをプレフィクスとして設定します。この種類の互換アドレスはトンネリング (詳しくは 13.2.3項 「IPv4 と IPv6 の共存」 をお読みください) で使用され、 IPv4 と IPv6 のホストが、純粋な IPv4 環境内で互いに通信できるようにするものです。
- IPv6 にマッピングされた IPv4 アドレス
この種類のアドレスは、純粋に IPv4 のアドレスを IPv6 表記になおしたものです。
- ローカルアドレス
ローカルアドレスとしては、下記の 2 種類のものが存在します:
- リンクローカル
この種類のアドレスは、ローカルのサブネット内でのみ使用することができます。この種類のアドレスを発信元または送信先に持つパケットは、インターネットや他のサブネットに配信すべきではありません。これらのアドレスに対しては、特別なプレフィクス (
fe80::/10) が設定され、末尾にはネットワークカードのインターフェイス ID と、残りはゼロで埋められたアドレスになります。この種類のアドレスは、同じサブネット内に存在する他のホストとの通信に使用し、自動設定を目的として使用します。- サイトローカル
この種類のアドレスは他のサブネットに配信してもかまわないものの、インターネットに対しては配信すべきではありません。企業内や団体内などの中でのみ使用すべきものです。イントラネットと呼ばれるネットワークで使用されるもので、 IPv4 で言うところのプライベートアドレスと同じ意味を持ちます。また、このアドレスには特殊なプレフィクス (
fec0::/10) が設定され、末尾にはネットワークカードのインターフェイス ID と 16 ビットのサブネット ID が入ります。なお、後の残りはゼロで埋められます。
IPv6 で全く新しい機能としては、それぞれのネットワークインターフェイスが複数のアドレスを持つのが一般的である、という機能があります。これにより、複数のネットワークにアクセスするにあたっても、同じインターフェイスを使用することができるようになります。これらのネットワークのうちいずれかは、 MAC アドレスと既知のプレフィクスを利用して完全に自動化された設定を行うことができます。そのため、 IPv6 が有効化されてさえいれば、ローカルネットワーク内の全てのホストがリンクローカルアドレスで通信できることになります。なお、 MAC アドレスが IPv6 アドレスの一部となることから、世界中で使用される IPv6 アドレスもまた唯一のものになります。アドレスの残りの部分は サイトトポロジ とか パブリックトポロジ などと呼ばれますが、これはコンピュータの接続するネットワークに従って決まります。
特定のコンピュータが異なるネットワークに属するコンピュータと通信を行う場合、少なくとも 2 種類のアドレスを必要とします。 1 つは ホームアドレス と呼ばれ、インターフェイス ID だけでなく、通常属するホームネットワークに関する識別子 (および対応するプレフィクス) を持つものです。ホームアドレスは固定のアドレスであり、通常は変化するものではありません。ただし、モバイルホスト宛の全てのパケットは、家庭内にいてもどこか別の場所にいても、必ず配信することができるようになっています。これは、 IPv6 で新しい機能として導入された ステートレス自動設定 と 近隣探索 によって実現されています。ホームアドレスに加えて、モバイルホストでは接続先に対応する 1 つ以上の追加アドレスが設定されます。これらは ケア・オブ (気付) アドレス と呼ばれます。また、ホームネットワークには、そのホストが別の場所にいるような場合に、そのホスト宛の通信を別の場所に転送する機能を備えています。 IPv6 環境では、この処理は ホームエージェント と呼ばれる仕組みが実装しています。これはホームアドレス宛の全てのパケットを、トンネルを介して中継する仕組みで、逆にケア・オブアドレス宛の通信は、特にパケットを迂回させることなくモバイルのホスト宛に転送されます。
13.2.3 IPv4 と IPv6 の共存 #Edit source
インターネットにおいて、全てのホストに対する IPv4 から IPv6 への移行は、順次進められている状況です。この場合は、両方のプロトコルが共存することになります。 1 つのシステム内での共存は、両方のプロトコルを実装する デュアルスタック の仕組みによって成り立っています。ただし、 IPv6 が有効化されたホストがどのようにして IPv4 のホストと通信するのか、および IPv6 パケットがどのように現在の (主に IPv4 ベースの) ネットワークで配送されていくのかが疑問になります。このような問題を解決するために、トンネリングと互換アドレスと呼ばれる仕組みが用意されています (詳しくは 13.2.2項 「アドレスの種類と構造」 をお読みください。
IPv6 のホストは (世界中にある) IPv4 ネットワーク内では孤立した存在で、トンネルを通して通信を行うことになります。 IPv6 パケットは IPv4 パケットとしてカプセル化され、 IPv4 のネットワークを移動します。このような IPv4 ホスト同士の接続を、 トンネル と呼びます。これを実現するためには、パケットには IPv6 の宛先アドレス (もしくは対応するプレフィクス) と、トンネルの出口となるリモートホストの IPv4 アドレスが含まれていなければなりません。ホストの管理者同士が合意して構築した基本的なトンネルは、 スタティック (静的) トンネリング と呼ばれます。
しかしながら、スタティックトンネリングの設定やメンテナンスには双方にとって手間のかかるもので、日々の負担にもなってしまいます。そのため、 IPv6 では 3 種類の ダイナミック (動的) トンネリング 方式が用意されています:
- 6over4
IPv6 パケットは自動的に IPv4 パケットとしてカプセル化され、マルチキャストに対応した IPv4 ネットワーク内に送信されます。 IPv6 からの見た目では、ネットワーク全体 (つまりインターネット) が巨大なローカルエリアネットワーク (LAN) であるかのように扱われます。これにより、 IPv4 トンネルの受信側を決定できることになります。しかしながら、インターネットの世界ではマルチキャストが十分に普及していないことから、この方法は規模の拡大には十分に対応できない状況です。そのため、この方法はマルチキャストを利用できる小さな企業や団体などに対する解決方法にとどまっています。なお、この方式の仕様は、 RFC 2529 に規定されています。
- 6to4
この方法を利用すると、 IPv6 アドレスから IPv4 アドレスを自動生成して、孤立した IPv6 ホストを IPv4 ネットワークと通信できるようにします。ただし、 IPv6 とインターネットとの間での通信に対して、いくつかの問題が報告されています。この方式は RFC 3056 に規定されています。
- IPv6 トンネルブローカー
この方法は、 IPv6 ホスト向けの専用トンネルを提供する特別なサーバを使用します。この方式は RFC 3053 に規定されています。
13.2.4 IPv6 の設定 #Edit source
IPv6 を設定するには、通常は個別のコンピュータに対して作業を行う必要はありません。これは、 IPv6 は既定で有効化されているためです。インストール済みのシステムで IPv6 を有効化もしくは無効化するには、 YaST を起動して モジュールを起動します。 のタブ内に、 のチェックボックスがありますので、必要に応じてチェックを入れるか外すかしてください。 また、再起動するまでの間、一時的に IPv6 を有効化するには、 root で modprobe -i ipv6 を実行します。なお、いったんモジュールを読み込んでしまうと、再起動以外の手段では読み込みを解除することができなくなりますので、ご注意ください。
IPv6 の自動設定の考え方により、ネットワークカードには リンクローカル のアドレスが割り当てられます。また、通常はワークステーション内でのルーティングテーブル管理は行いません。 ルータアドバタイズメントプロトコル を利用することで、ワークステーション側からネットワークルータに問い合わせを行い、プレフィクスと使用すべきゲートウエイに関する情報を取得します。通常は radvd プログラムを利用することで、 IPv6 ルータを構築します。そのほか、 FRR (詳しくは https://frrouting.org/ をお読みください) を利用して、アドレスとルーティングを自動設定することもできます。
/etc/sysconfig/network ファイルを利用して様々な種類のトンネルを設定する方法について、詳しくは ifcfg-tunnel のマニュアルページ ( man ifcfg-tunnel ) をお読みください。
13.2.5 さらなる情報 #Edit source
これまでの章での説明は、 IPv6 の一部のみをカバーしたものであって、全てを説明しているわけではありません。この新しいプロトコルに関するより詳しい情報をご希望の場合は、下記のオンライン文書やブックをご覧ください:
- https://pulse.internetsociety.org
IPv6 に関する全ての出発点です。
- http://www.ipv6day.org
ご自身で IPv6 ネットワークを始めるにあたっての情報が提供されています。
- http://www.ipv6-to-standard.org/
IPv6 対応の製品の一覧が提供されています。
- https://www.bieringer.de/linux/IPv6/
Linux における IPv6 の HOWTO や、 IPv6 関連の様々なリンクが提供されています。
- RFC 2460
IPv6 の RFC に関する基本情報については、 https://www.rfc-editor.org/rfc/rfc2460 をお読みください。
- IPv6 Essentials
Silvia Hagen 氏による IPv6 の主要な要素を説明した書籍です (ISBN 0-596-00125-8) 。
13.3 名前解決 #Edit source
DNS は 1 つもしくは複数の名前を IP アドレスに割り当てたり、逆に IP アドレスを名前に割り当てたりすることのできる仕組みです。 DNS サービスを提供する側の Linux では、この変換を bind と呼ばれる特別な種類のソフトウエアで賄います。サービスを提供する側のコンピュータを、一般に ネームサーバ と呼びます。また、 DNS は階層型のシステムで、それぞれの階層をピリオドで区切ります。ただし、 IP アドレスにある階層構造とは独立して運用されています。
たとえば jupiter.example.com のような完全な名前は、 ホスト名.ドメイン名 のような形式で記述します。この完全な名前を 完全修飾ドメイン名 (Fully Qualified Domain Name; FQDN) と呼びます。また、ドメイン名 (例: example.com ) の末尾は トップレベルドメイン (Top Level Domain; TLD) と呼びます。 上述の例では、 com がそれにあたります。
TLD の割り当ては、歴史的な事情から複雑になっています。以前は、 3 文字の TLD はアメリカ合衆国が使用し、残りの国では、 2 文字の ISO 国コードを TLD として使用していました。これに加えて、 2000 年にはより長い TLD が導入され、様々な用途で使用されるようになりました (例: .info , .name , .museum など) 。
インターネットが始まったばかりの頃 (1990 年以前) 、インターネット上の全マシンの名前を保存するために、 /etc/hosts が使われてきました。ところが、インターネットに接続するコンピュータの台数が爆発的に増えることによって、それは一瞬で非現実的なものになってしまいました。このような経験から、ホスト名を管理するための分散データベースを開発して、それを世界中に広げることにしました。このデータベースはネームサーバに似た仕組みで、インターネット内の全てのホストを保持するには不十分であるものの、他のネームサーバにリクエストを転送できる仕組みを備えていました。
階層構造の頂点には ルートネームサーバ と呼ばれるサーバが存在しています。これらのルートネームサーバは、トップレベルドメインを管理する存在で、ネットワークインフォメーションセンター (Network Information Center; NIC) が管理しています。それぞれのルートネームサーバは、どのネームサーバがどのトップレベルドメインを管理しているのかを知っています。トップレベルドメインの NIC は https://www.internic.net です。
DNS はホスト名の解決を行うだけではありません。ドメイン全体の電子メールを受信するホストなどの情報 (Mail Exchanger (MX)) も保持しています。
お使いのマシンから IP アドレスを解決できるようにするためには、少なくとも 1 台のネームサーバの IP アドレスが必要となります。 ネームサーバの設定を行うには、 YaST をお使いください。 また、 openSUSE® Leap における具体的なネームサーバ設定については、 13.4.1.4項 「ホスト名と DNS の設定」 をお読みください。独自のネームサーバを構築したい場合は、 第19章 「ドメインネームシステム」 をお読みください。
whois と呼ばれるプロトコルは、 DNS と密接な関係を持つプロトコルです。このプロトコルは、特定のドメインに対する管理情報などを問い合わせることができます。
注記: マルチキャスト DNS と .local ドメイン名について
.local のトップレベルドメイン名はリンクローカルドメインと呼ばれるもので、このドメイン宛の DNS リクエストは、通常の DNS リクエストではなく、マルチキャスト DNS リクエストとして送信されます。既に .local というドメインをネームサーバの設定で使用している場合は、 /etc/host.conf で無効化する必要があります。詳しくは host.conf のマニュアルページをお読みください。
インストール時にマルチキャスト DNS を使用しないようにするには、起動パラメータに nomdns=1 を指定してください。
マルチキャスト DNS についての詳細は、 http://www.multicastdns.org をお読みください。
13.4 YaST を利用したネットワークの設定 #Edit source
Linux では様々な種類のネットワークに対応しています。これらのうちのほとんどは、それぞれ異なるデバイス名を使用するもので、ファイルシステム内の様々な箇所に設定ファイルが分散しています。手作業でのネットワーク設定について、詳しくは 13.6項 「ネットワーク接続の手動管理」 をお読みください。
リンクの確立している (ケーブルが接続されている) 全てのインターフェイスが、自動的に設定されます。 インストール済みの状態でも、任意の時点で追加のハードウエアを設定することができます。下記の章では、 openSUSE Leap で対応している全種類のネットワーク接続に対して、その設定方法を説明しています。
13.4.1 YaST を利用したネットワークカードの設定 #Edit source
YaST でイーサネットや Wi-Fi, Bluetooth カードなどを設定したい場合は、 YaST を起動して › を選択します。モジュールを起動すると、 YaST は ウインドウ内で 4 つのタブを表示します。それぞれ , , , というタブになっています。
のタブでは、ネットワークの設定方法や IPv6 の利用可否、そして一般的な DHCP オプションなどを設定することができます。詳しくは 13.4.1.1項 「グローバルネットワークオプションの設定」 をお読みください。
タブには、インストール済みのネットワークカードとその設定が表示されます。ここには、検出済みのネットワークカードが名前で表示されます。このダイアログでは新しいネットワークカードの設定のほか、既存のネットワークカードの設定変更や削除も行うことができます。自動では検出されないネットワークカードを手作業で設定するには、 13.4.1.3項 「未検出のネットワークカードの設定」 の手順に従って作業を行ってください。また、既に設定済みのネットワークカードの設定を変更するには、 13.4.1.2項 「ネットワークカードの設定変更」 をお読みください。
のタブでは、マシンに設定するホスト名や、使用すべきネームサーバなどを設定します。詳しくは 13.4.1.4項 「ホスト名と DNS の設定」 をお読みください。
タブでは、ルーティングに関連する設定を行います。詳しくは 13.4.1.5項 「ルーティングの設定」 をお読みください。
図 13.3: ネットワークの設定 #
13.4.1.1 グローバルネットワークオプションの設定 #Edit source
YaST の モジュール内の タブでは、 NetworkManager や IPv6 の使用可否のほか、 DHCP クライアントオプションなどを設定することができます。これらの設定は、全てのネットワークインターフェイスに適用されます。
では、ネットワークの接続を管理するための方法を選択します。 NetworkManager のデスクトップアプレットを使用して全てのネットワークインターフェイスを管理したい場合は、 を選択します。 NetworkManager は有線ネットワークと無線ネットワークを切り替えて使用する場合にも便利な仕組みです。デスクトップ環境を動作させていない場合や、お使いのコンピュータが Xen サーバや仮想化システムであるような場合、もしくは DHCP や DNS などのネットワークサービスを提供しているような場合は、 を選択します。なお、 NetworkManager を使用する場合は、ネットワークの設定は nm-applet を利用して行うことになりますので、 , , などのタブは無効化され、選択できなくなります。 NetworkManager について、詳しくは 第28章 「NetworkManager の使用」 をお読みください。
では、 IPv6 プロトコルを使用するかどうかを選択します。 IPv6 は、 IPv4 と共に使用することができます。既定では IPv6 が有効化されています。しかしながら、 IPv6 を使用していないネットワークの場合は、 IPv6 プロトコルを無効化したほうが高速に動作しますので、この場合は のチェックを外してください。 IPv6 を無効化すると、カーネルは IPv6 モジュールを自動では読み込まなくなります。また、この設定は次回の再起動から有効になります。
では、 DHCP クライアントに対する設定を行うことができます。 はネットワーク内で唯一とならなければならない値を入力する項目で、何も指定しない場合はネットワークインターフェイスのハードウエアアドレスを使用します。ただし、同じネットワークインターフェイスを利用して複数の仮想マシンを動作させているような場合は、複数の仮想マシンが同じハードウエアアドレスになってしまいますので、それぞれで別々の識別子を入力する必要があります (記入に際してのルールはありません。自由記入です) 。
では、 DHCP クライアントが DHCP サーバに送信する際の、ホスト名オプションの値を文字列で指定します。 DHCP サーバによっては、ネームサーバのゾーン (正引きおよび逆引き) を更新しますが、この際に の値を利用して更新を行うものがあります (動的 DNS) 。また、 DHCP サーバによっては に特定の文字列が含まれていることを確認して、応答を送信するものもあります。なお、現在のホスト名を送信したい場合は、 AUTO のままにしておいてください (ホスト名は /etc/hostname に設定されます) 。また、何もホスト名を送信したくない場合は、何も入力しないでください。
また、 DHCP サーバからの情報でデフォルトルートを更新したくない場合は、 のチェックを外してください。
13.4.1.2 ネットワークカードの設定変更 #Edit source
ネットワークカードの設定を変更するには、 YaST の から、 タブを選択します。すると、検出されたカードの一覧が表示されますので、必要な項目を選んで を押します。すると、 ダイアログが表示されますので、必要に応じて , , の各設定を変更してください。
13.4.1.2.1 IP アドレスの設定 #Edit source
IP アドレスそのものの設定や、 IP アドレスの割り当て方法の設定を行う場合は、 ダイアログ内の タブで行います。ここでは IPv4 と IPv6 の両方に対応しています。ここでは、 (ボンディングデバイスとして使用する場合に指定します) のほか、 (IPv4 または IPv6) や のいずれかを選択します。なお、 を選択した場合は、 もしくは のいずれか、もしくはその両方を選択することができます。
また、 を選択した場合は、 (IPv4), (IPv6), のいずれかを選択します。
また、インストールの時点でリンクが確立しているネットワークカードがあれば、それらのうちの最初のネットワークカードが DHCP で設定されます。
DHCP は、インターネットサービスプロバイダ (Internet Service Provider; ISP) から固定の IP アドレスが割り当てられない DSL 回線をお使いの場合には、使用しておくべき設定となります。なお、 DHCP を使用する場合は、 ダイアログ内の 内にある についてもご確認ください。また、同じインターフェイスを利用して複数の仮想ホストを動作させるような場合は、それらを区別するために の設定が必要となる場合があります。
また、 DHCP はクライアント側を設定する際には適切な選択ではありますが、サーバとして設定する場合には不適切です。固定の IP アドレスを設定するには、下記の手順で行います:
YaST のネットワーク設定モジュールの タブ内で、検出されたネットワークカードのうちのいずれかを選択して、 を押します。
タブでは、 を選択します。
の欄にアドレスを入力します。 IPv4 と IPv6 の両方のアドレスを使用することができます。また、 にはネットマスクを指定します。 IPv6 アドレスの場合は、 の項目には
/64のような形式で指定します。また、必要であれば の欄に、完全修飾ドメイン名を指定することができます。この設定は
/etc/hosts内に書き込まれます。を押します。
設定を反映させるには、 を押します。
注記: インターフェイスの有効化とリンクの検出
ネットワークインターフェイスを有効化する際、 wicked は物理的なリンク状況を確認して、リンクが検出できた場合にのみ IP 設定を適用します。リンクの確率とは関係なくアドレスを設定したい場合 (たとえば特定のアドレスで待ち受けるサービスをテストしたいような場合) は、 /etc/sysconfig/network/ifcfg-インターフェイス名 設定ファイル内に LINK_REQUIRED=no を追加してください。
また、リンクを待機する秒数を指定したい場合は、 LINK_READY_WAIT=5 のような指定を行うこともできます。
ifcfg-* 設定ファイルについて、詳しくは 13.6.2.5項 「/etc/sysconfig/network/ifcfg-*」 および man 5 ifcfg をお読みください。
固定のアドレスを使用する場合は、ネームサーバやデフォルトゲートウエイも自動では設定されません。ネームサーバを設定するには 13.4.1.4項 「ホスト名と DNS の設定」 の手順を、デフォルトゲートウエイを設定するには 13.4.1.5項 「ルーティングの設定」 の手順をお読みください。
13.4.1.2.2 複数アドレスの設定 #Edit source
1 つのネットワークデバイスに対して、エイリアスやラベルとして複数の IP アドレスを設定することができます。
注記: エイリアス/ラベル機能について
エイリアスやラベルと呼ばれる機能は、 IPv4 でのみ動作します。 iproute2 を利用することで、ネットワークインターフェイスに複数のアドレスを設定できます。
YaST を利用してネットワークカードに追加のアドレスを設定するには、下記の手順で実施します:
YaST の ダイアログ内にある タブで、検出されたネットワークカードのうちいずれかを選択し、 を押します。
› で、 ボタンを押します。
それぞれ , , をそれぞれ指定します。なお、 IP エイリアスの場合は
/32のネットマスクでなければなりません。また、別名内にインターフェイス名は入れないでください。設定を有効化するには、 または を押してください。
13.4.1.2.3 デバイス名の変更と udev ルール #Edit source
使用するネットワークカードの名前については、必要に応じて変更することができます。ネットワークカード同士の判別は、ハードウエア (MAC) アドレスのほか、コンピュータ内のバス ID で行います。巨大なサーバを構成するような場合は、後者を指定しておくとネットワークカードを後から接続 (ホットプラグ) することができるようになります。これらの設定を YaST で行うには、下記の手順で行います:
YaST の ダイアログ内にある タブで、検出されたネットワークカードのうちいずれかを選択し、 を押します。
タブに移動します。現在のデバイス名が、 内に表示されています。ここから を押します。
まずはネットワークカードの識別方法を、 もしくは の中から選択します。それぞれ現在の MAC アドレスとバス ID がダイアログ内に表示されます。
デバイス名を変更するには、 の欄に新しいデバイス名を入力します。
設定を有効化するには、 または を押してください。
13.4.1.2.4 ネットワークカードのカーネルドライバの変更 #Edit source
ネットワークカードによっては、複数のカーネルドライバの中からいずれかを選択することができます。カードが既に設定済みの場合、 YaST では利用可能なドライバの一覧を表示して、その中からいずれかを選択することができます。また、ここではカーネルドライバに対するオプションを設定することもできます。 YaST で設定を変更するには、下記の手順で行います:
YaST の ダイアログ内の タブで、検出されたネットワークカードのうちいずれかを選択し、 を押します。
タブに移動します。
使用すべきカーネルドライバを、 の欄で選択します。また、
== 値 の形式で、 欄に必要なオプションを指定します。複数のオプションを指定したい場合は、スペースで区切って指定してください。設定を有効化するには、 または を押してください。
13.4.1.2.5 ネットワークデバイスの有効化 #Edit source
wicked を利用する方法を選択した場合、ネットワークデバイスをシステムの起動時に開始するか、ケーブルを接続したときに開始するか、カードを検出した際に開始するか、もしくは手作業で開始するか、何も有効化しないかを選択することができます。開始方法を変更するには、下記の手順で行います:
YaST から › を選択して、検出されたネットワークカードの中からいずれかを選択し、 を押します。
タブ内にある で、いずれかを選択します。
を選択すると、システムの起動時にデバイスが開始されます。 を選択すると、物理的な接続状況を監視して、接続が確認できると開始されます。 を選択すると、インターフェイスが利用可能な状態になると開始されます。これは の選択とほぼ同じ動作ですが、システムの起動時にデバイスが存在していなくても、エラーにならない点が異なります。また、 を選択すると、
ifupで手作業で開始する設定になります。 を選択すると、デバイスを開始しなくなります。また、 の選択肢は、 とほぼ同じ動作になりますが、systemctl stop networkを実行してもインターフェイスがシャットダウンされなくなります。また、wickedが有効な際は、networkサービスがwickedサービスの起動も扱うようになります。この選択肢は、 NFS や iSCSI を介してルートファイルシステムにアクセスする際に選択します。設定を有効化するには、 または を押してください。
ヒント: NFS をルートファイルシステムで使用する場合の注意
ルートパーティションを NFS 共有経由でマウントするシステム (ディスクを持たないシステム) の場合、 NFS 共有にアクセスするネットワークデバイスについては、設定を注意して行う必要があります。
システムをシャットダウンしたり再起動したりする際、既定の処理順序はネットワークの接続を切断してからルートパーティションをマウント解除しますが、ルートパーティションが NFS である場合、この順序で処理してしまうと、ネットワークが先に切れてしまうことから、 NFS のマウントを正しく解除することができなくなってしまいます。ネットワークデバイスが無効化されないようにするには、 13.4.1.2.5項 「ネットワークデバイスの有効化」 で説明しているとおりネットワークデバイスの設定ウインドウを開いて、 で を選択してください。
13.4.1.2.6 最大転送単位サイズの設定 #Edit source
インターフェイスに対しては、最大転送単位 (MTU) を設定することができます。 MTU とは、最も大きいパケットのサイズをバイト単位で表したもので、 MTU を大きくすればするほど、帯域を効率的に使用することができるようになります。ただし、遅いインターフェイスで MTU を大きくしすぎると、その送信にかかる時間が大きくなってしまい、インターフェイスを長い時間占有してしまうことになりますので、即時性が損なわれてしまいます。
YaST から › を選択して、検出されたネットワークカードの中からいずれかを選択し、 を押します。
タブを選択し、 の欄内にあるドロップダウンボックスで、値を入力するか選択を行います。
設定を有効化するには、 または を押してください。
13.4.1.2.7 PCIe 多機能デバイス #Edit source
LAN, iSCSI, FCoE のそれぞれに対応する多機能型デバイスを利用することができます。 YaST の FCoE クライアント ( yast2 fcoe-client ) では、ユーザ側で FCoE に使用するかどうかを選択できるようにするため、追加の列内にプライベートフラグが表示されます。 YaST のネットワークモジュール ( yast2 lan ) では、 「ストレージのみ」 に設定したネットワークインターフェイスは除外して表示します。
13.4.1.2.8 IP-over-InfiniBand (IPoIB) のための Infiniband 設定 #Edit source
YaST を起動し、 › を選択して、表示された Infiniband デバイスを選択して を押します。
タブでは、 (IPoIB) のモードのうち、 (既定値) もしくは の中からいずれかを選択します。
設定を有効化するには、 または を押してください。
InfiniBand について、詳しくは /usr/src/linux/Documentation/infiniband/ipoib.txt をお読みください。
13.4.1.2.9 ファイアウオールの設定 #Edit source
23.4項 「firewalld」 で説明している詳細なファイアウオール設定を行っていない場合は、ネットワークインターフェイスの設定手順のうちの 1 つで、基本的なファイアウオール設定を行うことができます。具体的には下記の手順で行います:
YaST を開いて、 › を選択します。 タブが表示されたら、検出済みのネットワークカードの一覧からいずれかを選択し、 を押します。
ダイアログ内にある タブを選択します。
内のリストボックスで、インターフェイスをどのゾーンに割り当てるのかを選択します。下記の選択肢が用意されています:
- ファイアウオールを無効にする
この選択肢はファイアウオールが無効化されていて、動作していない場合に表示されます。この設定は、別途のファイアウオールで保護された環境内に接続している場合にのみご利用ください。
- 自動ゾーン割り当て
このオプションはファイアウオールが有効化されている場合にのみ表示されます。ファイアウオールが動作すると、ファイアウオールがインターフェイスを自動的にゾーンに割り当てます。
anyというキーワードを含むゾーン、もしくは外部ゾーンのいずれかに割り当てられます。- 内部ゾーン (保護無し)
ファイアウオール自身は動作させるものの、このインターフェイスに対する保護ルールは何も適用しないゾーンです。この設定は、別途のファイアウオールで保護された環境内に接続している場合や、外部には全く接続していない場合にお使いください。
- 非武装ゾーン
非武装ゾーンとは、内部ネットワークの最前線に立つ追加のゾーンで、その外側には (攻撃を受けうる) インターネットが存在するゾーンです。このゾーンに割り当てられたホストは、内部ネットワークとインターネットの両方から接続することができますが、インターネット側から内部にはアクセスさせない構成を取るのが一般的です。
- 外部ゾーン
このインターフェイスでファイアウオールを動作させ、全てのネットワークトラフィックに対して (特に攻撃などから) 保護を適用するゾーンです。この選択肢が既定値になっています。
設定を有効化するには、 または を押してください。
13.4.1.3 未検出のネットワークカードの設定 #Edit source
ネットワークカードが正しく検出されなかった場合は、検出済みのネットワークインターフェイスの一覧内には表示されません。お使いのネットワークカード向けのドライバが存在することがわかっている場合は、手作業で設定を行うことができます。このほか、ネットワークブリッジやボンディング、 TUN や TAP と呼ばれる特殊なネットワークインターフェイスについても、手作業で設定を行うことになります。具体的には、下記の手順で行います:
YaST から › › を選び、 ボタンを押します。
内では、まず を選択し、 で選択または入力を行います。お使いのネットワークカードが USB デバイスである場合は、対応するチェックボックスにチェックを入れてから を押します。それ以外のデバイスである場合は、 にカーネルのモジュール名を入力し、必要であれば に必要なオプションを設定します。
なお、 では、
ifupコマンドでインターフェイスを起動する際、ethtoolコマンドに指定するオプションを設定します。利用可能なオプションの一覧については、ethtoolのマニュアルページをお読みください。オプションの文字列が
-で始まるものの場合 (たとえば-K インターフェイス名 rx onなど) は、文字列内の 2 番目の箇所が現在のインターフェイス名に置き換えられます。それ以外の場合 (たとえばautoneg off speed 10) は、ifupコマンドを実行する際、冒頭に-s インターフェイス名を追加します。を押します。
あとは IP アドレスやデバイスの有効化、インターフェイスに割り当てるファイアウオールのゾーンなど、残りのオプションを , , で設定します。設定項目についての詳細は、 13.4.1.2項 「ネットワークカードの設定変更」 をお読みください。
なお、 で を選択した場合は、次のダイアログで無線関連の設定を行います。
新しいネットワーク設定を有効化するには、 または を押してください。
13.4.1.4 ホスト名と DNS の設定 #Edit source
インストールの時点でお使いのネットワークカードが利用できる状態であり、かつネットワークの設定を変更していない場合は、お使いのコンピュータに対してホスト名が自動生成され、 DHCP が有効化された状態になります。これはネットワーク環境に接続するためのネームサーバの設定についても同様です。ネットワークアドレスを DHCP 経由で取得していると、ネームサーバの情報を受信した際に自動的に設定を行います。何らかの理由により、手作業で設定を行いたい場合は、これらの設定を行う必要があります。
お使いのコンピュータの名前や使用するネームサーバの検索リストを変更するには、下記の手順で行います:
YaST を起動し、 › を選択して、 タブを選択します。
まずは の欄にホスト名を指定します。なお、ホスト名はコンピュータ全体に対する設定であり、全てのネットワークインターフェイスに設定されることに注意してください。
IP アドレスを取得するのに DHCP を使用している場合は、 DHCP 側から通知された名前がホスト名として自動設定されます。このような動作は、複数のネットワークに接続する環境では、ホスト名が頻繁に変わる結果になることから、グラフィカルデスクトップ環境に悪影響を及ぼすこともありますので、無効化しておくことをお勧めします。 DHCP で IP アドレスを取得する環境で、ホスト名を変更しないようにするには、 を に設定してください。
また、 では、 DNS まわりの設定 (ネームサーバ、検索リスト、
/run/netconfig/resolv.confの内容) の修正方法を設定することができます。を選択すると、設定内容は
netconfigスクリプトが処理を行い、固定で設定された内容 (YaST もしくは設定ファイル内で設定した内容) と動的に取得した内容 (DHCP クライアントもしくは NetworkManager) を合成します。通常は、この既定のポリシーのままで問題ありません。を選択すると、
netconfigが/run/netconfig/resolv.confを変更しないようになります。ただし、このファイルは手作業で編集して変更することが可能です。を選択した場合は、 で指定した文字列の合成ポリシーで制御が行われます。ここにはカンマ区切りでインターフェイス名を指定し、指定したインターフェイスからの情報を正しい情報源と見なして、設定を書き換える動作を行います。インターフェイス名は、そのまま指定するだけでなく、ワイルドカードを指定することもできます。たとえば
eth* ppp?のように指定すると、ethで始まるインターフェイスと、ppp0からppp9が該当するようになります。このほか、/etc/sysconfig/network/configファイルで定義されている下記のキーワードも指定することができます:STATIC固定で設定した内容を、動的に取得した内容と合成する必要があることを指定します。
STATIC_FALLBACK動的に設定が取得できない場合にのみ、固定の設定を使用するよう指定します。
さらに詳しい情報については、
netconfig(8) のマニュアルページ (man 8 netconfig) をお読みください。と に対して、それぞれ必要な設定を行います。ネームサーバに対しては、ホスト名ではなく IP アドレス (例: 192.168.1.116) で設定してください。また、 には、ドメイン名無しでホスト名のみを指定した場合に、自動的に補完されるべきドメイン名を指定します。複数のドメインを に指定したい場合は、カンマまたはスペースで区切ってください。
設定を有効化するには、 または を押してください。
このほか、 YaST を利用してコマンドラインからホスト名を変更することもできます。YaST で変更を行った場合、その設定は即時に反映されます (/etc/hostname を編集した場合とは異なります) 。ホスト名を変更するには、下記のコマンドを実行します:
# yast dns edit hostname=ホスト名ネームサーバを変更したい場合は、下記のようなコマンドを実行します:
#yast dns edit nameserver1=192.168.1.116#yast dns edit nameserver2=192.168.1.117#yast dns edit nameserver3=192.168.1.118
13.4.1.5 ルーティングの設定 #Edit source
お使いのマシンを他のネットワーク内にあるマシンと通信したい場合は、ルーティング (経路制御) に関する情報を設定して、正しい経路で通信が配送されるように設定しなければなりません。 DHCP をお使いの場合、この情報は自動的に提供され適用されます。固定の設定をお使いの場合は、このデータは手作業で設定しなければなりません。
YaST を起動して、 › を選択します。
の IP アドレスを入力します (必要であれば、 IPv4 だけでなく IPv6 でも設定することができます) 。デフォルトゲートウエイは、その他のルーティング情報内に存在しなかった場合に、最後に使用すべき (既定の) ゲートウエイ (中継器) を意味するものです。
の欄を利用することで、さらに細かい設定を行うことができます。ここでは、 に通信先の IP アドレスを、 には使用するゲートウエイの IP アドレスを、 にはネットマスクをそれぞれ指定します。また、 の欄には、使用すべきネットワークインターフェイスの名前を指定します (
-を指定すると、任意のデバイスを使用する意味になります) 。 これらの値のうちのいずれかを省略したい場合は、マイナス記号-を指定してください。また、表内にデフォルトゲートウエイを設定したい場合は、 欄にdefaultと入力してください。
注記: ルートの優先制御
複数のデフォルトゲートウエイを使用する場合は、メトリック値を指定して優先順位を指定することができます。メトリック値を設定するには、 の欄に
- metric 数値の形式で指定を行います。設定可能なメトリック値の最小は 0 で、最も小さなメトリック値のルートが最優先とされ、既定で使用されます。ネットワークデバイスの接続が切れた場合は、ルーティング情報からその経路が削除され、次に有効なルーティングを使用します。お使いのシステムをルータとして設定するには、 内にある と をそれぞれ選択してください。
設定を有効化するには、 または を押してください。
13.5 NetworkManager #Edit source
NetworkManager はラップトップ機など、可搬性のあるコンピュータでは便利な仕組みです。 NetworkManager を利用することで、特にネットワークを頻繁に切り替えて利用するような環境の場合、ネットワークインターフェイスの設定を心配する必要がなくなります。
13.5.1 NetworkManager と wicked の違い #Edit source
しかしながら、 NetworkManager が全ての用途において適切な選択肢であるとは言えないのが現状です。そのため、現時点でも wicked による制御方式と NetworkManager による制御方式のいずれかを選択するようになっています。 NetworkManager を利用してネットワーク接続を管理したい場合は、まず YaST のネットワーク設定モジュールで設定を行ってください。こちらについて、詳しくは 28.2項 「NetworkManager の有効化と無効化」 をお読みのうえ、設定を行ってください。また、 NetworkManager の使用例や設定方法についての詳しい説明は、 第28章 「NetworkManager の使用」 をお読みください。
wicked と NetworkManager には、いくつかの違いがあります:
rootの権限ネットワーク設定を NetworkManager で行う場合、アプレットを使用すれば、お使いのデスクトップから簡単にネットワークの接続を切り替えたり、開始もしくは停止したりすることができます。 NetworkManager では、
rootの権限無しに、無線 LAN カードの接続を変更したり管理したりすることもできます。このような理由から、 NetworkManager はモバイル端末では魅力的なソリューションとなります。wickedでもネットワーク接続の切り替えや開始/停止などに対応していて、ユーザが明示的に介在していなくても、自分自身で管理しているかのように扱うことができます。ただし、これらの作業にはいずれもrootの権限が必要となります。また、全ての接続をあらかじめ設定しておかなければならないことにもなりますので、モバイル環境では使いづらくなってしまいます。- ネットワーク接続の種類
wickedであっても NetworkManager であっても、有線 LAN だけでなく、無線 LAN の接続を扱うことができます (WEP, WPA-PSK, WPA-Enterprise などに対応しています) 。また、 DHCP による自動設定や固定の設定にも対応しています。このほか、ダイヤルアップ接続や VPN にも対応しています。ただし、ブロードバンド (3G) モデムや DSL 接続を扱うことができるのは NetworkManager だけで、従来の設定方式では扱うことができません。NetworkManager では、お使いのコンピュータで常に最適な接続を使用するように努めています。ネットワークケーブルが外れてしまったような場合でも、再接続を試みるようになっています。また、無線 LAN 接続の設定が存在する場合、設定されているものの中で最も信号強度が強いものを検出して、それに接続するように動作します。
wickedを利用してこれを行うとすると、さらなる設定作業が必要となってしまいます。
13.5.2 NetworkManager の機能と設定ファイル #Edit source
NetworkManager で作成した個別のネットワーク接続設定は、設定プロファイル内に保存されます。 NetworkManager や YaST で設定した システム 接続は、 /etc/NetworkManager/system-connections/* もしくは /etc/sysconfig/network/ifcfg-* 内に保存されます。 GNOME の場合、全てのユーザ定義接続は GConf 内に保存されます。
何もプロファイルを設定していない場合、 NetworkManager は自動的にプロファイルを作成し、そのプロファイルに Auto $INTERFACE-NAME という名前を設定します。これは、できる限り多くの場合において、設定を行うことなくネットワークを動作させる意図で作られたものですが、これが要件に適合しない場合は、 GNOME などで提供されているネットワーク接続ダイアログを利用して、変更を行ってください。詳しくは 28.3項 「ネットワーク接続の設定」 をお読みください。
13.5.3 NetworkManager の機能制御とロックダウン #Edit source
集中管理されているマシンなどの場合は、特定の NetworkManager 機能を無効化したり Polkit で無効化したりすることができます。たとえばユーザは管理者が設定した接続のみを変更できるようにするとか、ユーザは独自のネットワーク接続のみを利用できる、などがあります。 NetworkManager のポリシーを表示もしくは変更するには、 Polkit のグラフィカルな ツールを利用してください。左側のツリー表示に という項目があるはずです。 Polkit とその設定方法について、詳しくは 第18章 「Polkit 認可フレームワーク」 をお読みください。
13.6 ネットワーク接続の手動管理 #Edit source
ネットワークインターフェイスの手動設定は最後の選択肢として用意されています。通常は YaST の使用をお勧めしますが、下記に示す背景となる情報を知っておくことで、 YaST での設定もよりわかりやすくなります。
13.6.1 wicked ネットワーク設定 #Edit source
wicked と呼ばれるツールとライブラリが、ネットワーク設定に対する新しいフレームワークを提供しています。
以前のネットワークインターフェイス管理では、異なるレイヤのネットワーク管理を寄せ集めて単一のスクリプトにするか、あっても 2 つの異なるスクリプトに仕立て上げるものでした。これらのスクリプトは、きちんと定義されていない方法で互いに作用するものであり、これによって予期しない問題を発生させたり、不明瞭な制約や慣習などをもたらしたりする結果になってしまっていました。また、様々なシナリオに対応するための様々なレイヤの特殊な修正により、さらにメンテナンスを複雑化させてしまっていました。アドレス設定プロトコルは dhcpcd のような実装を介して使用されていましたが、こちらも他のインフラストラクチャとの対話性は低いままでした。また、わけのわからないインターフェイス名の命名方式によって、インターフェイス名の永続性を達成するのに udev の支援を多く必要としてしまっていました。
wicked は、様々な方法でこれらの問題を切り分けるために作られています。いずれの箇所も奇抜なものではないものの、様々なプロジェクトからのアイディアをまとめて、全体的によりよいソリューションとなるよう期待が込められています。
1 つ目のアプローチは、クライアント/サーバモデルの採用です。これにより、 wicked はフレームワーク全体と十分に統合された仕組みの中で、アドレス設定などの標準化された仕組みを定義することができるようになっています。たとえば特定のアドレス設定を行う場合、管理者は DHCP や IPv4 Zeroconf などを使用するよう設定する場合がありますが、この場合もサーバからアドレスの貸与情報を取得して、それを wicked のサーバプロセスに渡すことで、 wicked 側がそのアドレスと経路の設定を行うようになっています。
問題を切り分けるためのもう 1 つのアプローチとしては、レイヤ構造をきちんと守っているということが挙げられます。どのような種類のネットワークインターフェイスであっても、ネットワークインターフェイスのデバイスレイヤ (VLAN, ブリッジ, ボンディング, 準仮想化デバイスなど) を設定する DBus サービスを定義することができるようになっています。アドレスの設定などの一般的な機能については、それぞれを特別に実装することなくデバイス固有のサービス上に搭載することのできる、接続サービスを用いて実装されています。
wicked フレームワークは、これら 2 つの要素を様々な DBus サービスを利用して実装しています。使用する DBus サービスはネットワークの種類によって異なりますが、ここには wicked 内での現在のオブジェクト構造について、大まかな概要を示しています。
それぞれのネットワークインターフェイスは /org/opensuse/Network/Interfaces の子オブジェクトとして表されます。子オブジェクトの名前は ifindex の値から設定されます。たとえばループバックインターフェイスの場合、通常は ifindex が 1 になりますので、 /org/opensuse/Network/Interfaces/1 になります。最初に登録されたイーサネットインターフェイスは、 /org/opensuse/Network/Interfaces/2 になります。
それぞれのネットワークインターフェイスには 「クラス」 が割り当てられ、対応する DBus インターフェイスを選択する際に使用します。既定では、各ネットワークインター他フェイスは netif というクラスになっていて、 wickedd はこのクラスと互換性のある全てのインターフェイスに自動的に接続するようになっています。また、現在の実装では、下記のインターフェイスが含まれています:
- org.opensuse.Network.Interface
リンクアップやリンクダウン、 MTU の割り当てなどの一般的なネットワークインターフェイス機能を表します。
- org.opensuse.Network.Addrconf.ipv4.dhcp, org.opensuse.Network.Addrconf.ipv6.dhcp, org.opensuse.Network.Addrconf.ipv4.auto
DHCP, IPv4 zeroconf などのアドレス設定サービスを表します。
これらに加えて、ネットワークインターフェイスによっては特別の設定機構を必要としていたり、提供していたりすることがあります。たとえばイーサネットデバイスであれば、リンク速度やチェックサムのオフロード機能などを制御することができるでしょう。これらを実現するために、イーサネットの場合は netif のサブクラスであるnetif-ethernet という特殊なクラスが用意されています。そのため、イーサネットインターフェイスに割り当てられている DBus インターフェイスは、上述の全てのサービスに加えて、 org.opensuse.Network.Ethernet サービスが提供されています。これにより、 netif-ethernet クラスに属するオブジェクトにアクセスできるようになっています。
同様に、ブリッジや VLAN 、ボンディングや InfiniBand 等のインターフェイスの種類に対しても、それぞれのクラスが用意されています。
VLAN のように、イーサネットデバイスを包含するタイプの仮想ネットワークインターフェイスである場合、これらを先に作成する必要がありますが、これは wicked でどのように扱われているのでしょうか? これを実現するために、 wicked では org.opensuse.Network.VLAN.Factory などの factory インターフェイスを定義しています。この factory インターフェイスは、指定した種類のインターフェイスを作成する機能だけを持ち、このインターフェイスが /org/opensuse/Network/Interfaces のリストノードに割り付けられるようになっています。
13.6.1.1 wicked の構造と機能 #Edit source
wicked サービスは複数のパーツから構成されています。詳しくは 図13.4「wicked の構造」 をお読みください。
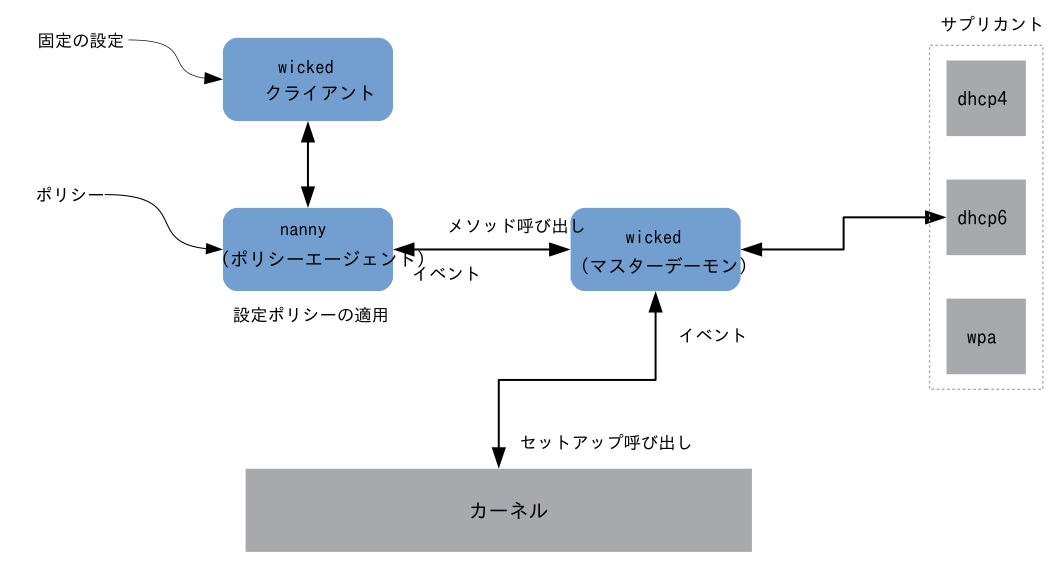
図 13.4: wicked の構造 #
wicked には現在、下記のものが含まれています:
SUSE 形式の
/etc/sysconfig/networkファイルを処理するための設定ファイルバックエンドネットワークの設定を XML 形式で表す内部用の設定バックエンド
イーサネットや InfiniBand, VLAN,ブリッジ, ボンディング, TUN, TAP,ダミー, macvlan, macvtap, hsi, qeth, iucv, および無線 (現時点では WPA-PSK/EAP のみ) などの 「一般的な」 インターフェイスの起動と停止
内蔵型の DHCPv4 クライアントおよび DHCPv6 クライアント
設定済みのインターフェイスが利用可能な状態になった場合の自動起動 (ホットプラグ) と、リンク (キャリア) を検出した際の IP 設定に対応する nanny デーモン (既定で有効化されています) 。詳しくは 13.6.1.3項 「Nanny」 をお読みください
systemd と統合するための DBus サービスの集合体としての実装 (そのため、通常の
systemctlのコマンドがwickedにも適用されます)
13.6.1.2 wicked の使用 #Edit source
openSUSE Leap では、 wicked はデスクトップハードウエアやサーバハードウエアの場合に、既定で動作しています。モバイルハードウエアの場合は、 NetworkManager が既定で動作しています。現時点で何が有効化され動作しているのかを調べるには、下記のコマンドを実行します:
systemctl status network
wicked が有効化されている場合、下記のような出力が現れます:
wicked.service - wicked managed network interfaces
Loaded: loaded (/usr/lib/systemd/system/wicked.service; enabled)
...何か異なるシステム (たとえば NetworkManager) が動作しているような場合で、 wicked に切り替えたい場合は、まず動作しているものを停止してから wicked を有効化してください:
systemctl is-active network && \ systemctl stop network systemctl enable --force wicked
これにより wicked サービスが有効化され、 network.service から wicked.service に別名リンクが設定され、次回以降の起動で開始されるようになります。
サーバプロセスを開始するには、下記のコマンドを実行します:
systemctl start wickedd
これにより、 wickedd (メインサーバ) が起動され、関連する下記のプログラムも起動されます:
/usr/lib/wicked/bin/wickedd-auto4 --systemd --foreground /usr/lib/wicked/bin/wickedd-dhcp4 --systemd --foreground /usr/lib/wicked/bin/wickedd-dhcp6 --systemd --foreground /usr/sbin/wickedd --systemd --foreground /usr/sbin/wickedd-nanny --systemd --foreground
あとはネットワークを起動します:
systemctl start wicked
上記ではなく、別名である network.service のほうを起動してもかまいません:
systemctl start network
これらのコマンドは既定値を使用するか、もしくは /etc/wicked/client.xml 内に書かれているシステム設定を使用します。
デバッグを有効化するには、 /etc/sysconfig/network/config 内で WICKED_DEBUG を設定します。たとえば下記のようになります:
WICKED_DEBUG="all"
下記のようにいくつかのデバッグ項目を省いてもかまいません:
WICKED_DEBUG="all,-dbus,-objectmodel,-xpath,-xml"
全てのインターフェイスに対する情報を表示したり、 インターフェイス名 で指定したインターフェイスに対する情報を表示したりするには、下記のいずれかを実行します:
wicked show all wicked show インターフェイス名
XML 形式で出力させたい場合は、下記のように実行します:
wicked show-xml all wicked show-xml インターフェイス名
いずれか 1 つのインターフェイスを起動する場合は、下記のように実行します:
wicked ifup eth0 wicked ifup wlan0 ...
何も設定情報を指定しない場合、 wicked クライアントは /etc/wicked/client.xml 内で指定されている既定の情報源を利用して設定しようとします:
firmware:iSCSI 起動ファームウエアテーブル (iBFT)compat:ifcfgファイル (互換性を維持するために実装されています)
wicked がインターフェイスの設定を取得した場合は、どのような内容であっても、 firmware , compat の順序で計画されています。ただし将来的には変更される可能性があります。
詳しくは wicked のマニュアルページをお読みください。
13.6.1.3 Nanny #Edit source
nanny はイベントおよびポリシー駆動型のデーモンで、ホットプラグ型のデバイスなどの非同期かつ不用意なシナリオに対応するための仕組みです。そのため、 nanny デーモンは開始や再起動の遅延のほか、一時的に取り外されたデバイスにも対応することができます。また、 nanny はデバイスとリンク状態の変更を監視しているほか、現在のポリシーセットで設定されている新しいデバイスを統合することができます。 Nanny では指定されたタイムアウト制約によって ifup が既に終了してしまったような場合でも、継続して設定を行うことができます。
既定では、 nanny デーモンはシステム内で有効化されています。具体的には、/etc/wicked/common.xml 設定ファイル内の下記で有効化されています:
<config> ... <use-nanny>true</use-nanny> </config>
この設定により、 ifup と ifreload は nanny デーモンに対して効率的な設定ポリシーを適用することになります。その後、 nanny は wickedd をも設定しますので、ホットプラグにも対応することになります。また、 nanny は裏でイベントや変更 (新しいデバイスの接続やキャリア状態の変更など) を待機する処理も行います。
13.6.1.4 複数のインターフェイスの開始 #Edit source
ボンディングやブリッジでは、複数のデバイスを 1 つにまとめて設定を行い (ifcfg-bondX) ますので、それらを一括で起動する必要があります。 wicked では、ボンディングやブリッジなどの上位側のインターフェイス名を起動するだけで、その中にあるインターフェイスを一括で起動することができます:
wicked ifup br0
このコマンドを実行すると、ブリッジを設定して起動するまでの処理を、特に依存関係の順序 (ポートなど) を指定することなく、自動で行うことができます。
複数のインターフェイスを 1 つのコマンドで起動するには、下記のように実行します:
wicked ifup bond0 br0 br1 br2
全てのインターフェイスを一括で起動するには、下記のように実行します:
wicked ifup all
13.6.1.5 Wicked によるトンネルの使用 #Edit source
wicked でトンネルを使用する必要がある場合は、 TUNNEL_DEVICE で設定を行って対応することができます。必要であれば、デバイス名を指定してトンネルとデバイスを紐づけることもできます。トンネルされたパケットは、このデバイスを介して配信されることになります。
詳しくは man 5 ifcfg-tunnel をお読みください。
13.6.1.6 差分変更の処理 #Edit source
wicked では、インターフェイスを再設定するにあたって、インターフェイスをいったん停止する必要はありません (カーネル側で求められている場合を除きます) 。たとえばネットワークインターフェイスに IP アドレスを追加したり、経路設定を行ったりする場合でも、インターフェイスの設定に IP アドレスを追加したあと、もう一度 「ifup」 操作を行うだけで済むようになっています。サーバ側では変更すべき設定のみを抽出して適用する処理を行います。これは MTU や MAC アドレスなどのリンクレベルのオプションだけでなく、アドレスや経路、アドレスの設定モード (固定のアドレス設定から DHCP への変更など) のネットワークレベルの設定に対しても、このような動作をするようになっています。
ブリッジやボンディングなど、複数の実デバイスから構成される仮想デバイスの設定に対しては、注意する必要があります。たとえばボンディングデバイスの場合、デバイスの起動中には特定の設定を行うことができません。設定しようとすると、エラーが発生することがあります。
しかしながら、ボンディングやブリッジなどの実デバイスの追加や削除、ボンディングにおけるプライマリインターフェイスの選択などは、行うことが可能です。
13.6.1.7 wicked 拡張: アドレス設定 #Edit source
wicked はシェルスクリプトによって拡張を行うことができます。これらの拡張は、 config.xml ファイル内に定義されています。
現時点では、いくつかの拡張クラスに対応しています:
リンク設定: これらは、クライアント側から提供されたリンクレイヤの設定にあわせてデバイスを設定し起動する機能、およびデバイスを停止するためのスクリプトです。
アドレス設定: これらは、デバイスのアドレス設定を行うためのスクリプトです。通常はアドレスの設定や DHCP の設定などは
wicked自身が管理しますが、拡張として実装もされています。ファイアウオール拡張: これらのスクリプトは、ファイアウオールのルールを適用します。
一般的に、拡張には開始と停止のコマンドが用意されているほか、必要に応じて 「PID ファイル」 やスクリプトに渡される環境変数などが存在しています。
拡張がどのように動作するのかを知るには、 etc/server.xml 内にあるファイアウオール拡張をご覧ください:
<dbus-service interface="org.opensuse.Network.Firewall"> <action name="firewallUp" command="/etc/wicked/extensions/firewall up"/> <action name="firewallDown" command="/etc/wicked/extensions/firewall down"/> <!-- default environment for all calls to this extension script --> <putenv name="WICKED_OBJECT_PATH" value="$object-path"/> <putenv name="WICKED_INTERFACE_NAME" value="$property:name"/> <putenv name="WICKED_INTERFACE_INDEX" value="$property:index"/> </dbus-service>
拡張は <dbus-service> タグに割り当てられ、このインターフェイスのアクションを実行する際のコマンドを定義しています。また、アクションに対して渡される環境変数の定義を行うこともできます。
13.6.1.8 wicked 拡張: 設定ファイル #Edit source
Wicked では、スクリプトを利用して設定ファイルの処理を拡張することができます。たとえば DHCP による貸与情報からの DNS の書き換えは、 extensions/resolver が実施していて、これは server.xml 内に記述されています:
<system-updater name="resolver"> <action name="backup" command="/etc/wicked/extensions/resolver backup"/> <action name="restore" command="/etc/wicked/extensions/resolver restore"/> <action name="install" command="/etc/wicked/extensions/resolver install"/> <action name="remove" command="/etc/wicked/extensions/resolver remove"/> </system-updater>
wickedd に対して更新が届くと、貸与情報を処理して、 resolver スクリプトの対応するコマンド ( backup , install など) を実行します。ここから /sbin/netconfig を呼び出して DNS の設定を変更するか、手作業で /run/netconfig/resolv.conf を変更している場合は、このファイルを直接変更する処理を行います。
13.6.2 設定ファイル #Edit source
本章では、ネットワーク関連の設定ファイルの概要とそれらの目的、そして使用する書式について説明しています。
13.6.2.1 /etc/wicked/common.xml #Edit source
/etc/wicked/common.xml ファイルには、全てのアプリケーションが使用する一般的な設定が記述されています。このファイルは、同じディレクトリ内にある他の設定ファイルから取り込まれる形で使用されます。なお、全ての wicked コンポーネントを一括でデバッグする目的で使用することもできますが、このような場合は /etc/wicked/local.xml ファイルをお使いください。また、ソフトウエアの更新が行われた場合は、 /etc/wicked/common.xml ファイルが上書きされ、元の設定が失われることがある点にも注意してください。なお、 /etc/wicked/common.xml ファイルは既定で /etc/wicked/local.xml ファイルを取り込むようになっていますので、特別な理由が無い限り、 /etc/wicked/common.xml ファイルを編集する必要はないはずです。
nanny を無効化する目的で <use-nanny> を false に設定した場合は、 wickedd.service サービスの再起動に加えて、下記のコマンドを実行して全ての設定とポリシーを適用してください:
>sudowicked ifup all
注記: 設定ファイル
wickedd , wicked , nanny の各プログラムは、自分専用の設定ファイルが存在していない場合、 /etc/wicked/common.xml ファイルを読み込みます。
13.6.2.2 /etc/wicked/server.xml #Edit source
/etc/wicked/server.xml ファイルは wickedd サーバプロセスが起動時に読み込むファイルです。このファイルには /etc/wicked/common.xml に対する追加の設定を記述します。具体的には、リゾルバの処理方法や DHCP などの addrconf から受信した情報の処理方法を設定します。
なお、このファイルに対して何らかの設定を追加したい場合は、 /etc/wicked/server-local.xml ファイルに記述することをお勧めします。このファイルは /etc/wicked/server.xml から取り込まれるようになっています。このように別途のファイルにすることで、メンテナンス更新後も設定内容を失わないようにすることができます。
13.6.2.3 /etc/wicked/client.xml #Edit source
/etc/wicked/client.xml ファイルは wicked コマンドが使用するファイルです。このファイルには ibft が管理するデバイスを検出した際に使用するスクリプトの場所や、ネットワークインターフェイスの設定などを記述します。
なお、このファイルに対して何らかの設定を追加したい場合は、 /etc/wicked/client-local.xml ファイルに記述することをお勧めします。このファイルは /etc/wicked/client.xml から取り込まれるようになっています。このように別途のファイルにすることで、メンテナンス更新後も設定内容を失わないようにすることができます。
13.6.2.4 /etc/wicked/nanny.xml #Edit source
/etc/wicked/nanny.xml ファイルはリンクレイヤの種類を設定するためのファイルです。このファイルに対して何らかの設定を追加したい場合は、 /etc/wicked/nanny-local.xml ファイルに記述することをお勧めします。このように別途のファイルにすることで、メンテナンス更新後も設定内容を失わないようにすることができます。
13.6.2.5 /etc/sysconfig/network/ifcfg-* #Edit source
これらのファイルには、ネットワークインターフェイスに対する従来の設定が含まれています。
注記: wicked と ifcfg-* ファイルの関係性について
wicked は compat: プレフィクスを指定した場合、これらのファイルを読み込むようになります。 openSUSE Leap の既定の /etc/wicked/client.xml 設定では、 wicked が /etc/wicked/ifconfig 内にある XML ファイルを読み込むよりも前に、これらのファイルを読み込むようになっています。
また、 --ifconfig スイッチはほぼテスト用にのみ提供されているものです。これを指定した場合、 /etc/wicked/ifconfig 内に設定されている既定の設定ソースは適用されなくなります。
ifcfg-* ファイルには起動モードや IP アドレスなどの情報が含まれています。設定可能なパラメータについて、詳しくは ifup のマニュアルページをお読みください。これに加えて、特定の 1 つのインターフェイスにのみ一般的な設定を適用したい場合は、 dhcp ファイルや wireless ファイルにある変数のうちのほとんどを使用することができます。ただし、 /etc/sysconfig/network/config の変数のうちのほとんどはグローバルなものであり、 ifcfg ファイルでは上書きできません。たとえば NETCONFIG_* 変数などがそれに該当します。
macvlan や macvtab インターフェイスを設定したい場合は、 ifcfg-macvlan および ifcfg-macvtap の各マニュアルページをお読みください。たとえば ifcfg-macvlan0 というファイルで macvlan インターフェイスを使用したい場合は、下記のように記述します:
STARTMODE='auto' MACVLAN_DEVICE='eth0' #MACVLAN_MODE='vepa' #LLADDR=02:03:04:05:06:aa
ifcfg.template に関する詳細は、 13.6.2.6項 「/etc/sysconfig/network/config , /etc/sysconfig/network/dhcp , /etc/sysconfig/network/wireless」 をお読みください。
13.6.2.6 /etc/sysconfig/network/config , /etc/sysconfig/network/dhcp , /etc/sysconfig/network/wireless #Edit source
config ファイルには ifup , ifdown ,ifstatus などのコマンドに対する一般的な設定が含まれています。また dhcp ファイルには DHCP に関する設定が、 wireless には無線 LAN カードに関する設定がそれぞれ含まれています。なお、 3 つの設定ファイルには、それぞれコメントで変数の説明が書かれています。 /etc/sysconfig/network/config ファイル内の設定のうちのいくつかは ifcfg-* ファイルでも使用することができます。なお、この場合は ifcfg-* 側での設定が優先されます。また、 /etc/sysconfig/network/ifcfg.template ファイルには、各インターフェイスに対して設定することのできる変数の一覧が書かれています。ただし、 /etc/sysconfig/network/config 内のほとんどの変数はグローバルなものであり、 ifcfg ファイルでは上書きできません。たとえば NETWORKMANAGER 変数や NETCONFIG_* 変数などがそれに該当します。
注記: DHCPv6 の使用について
DHCPv6 を使用する場合、ネットワーク内にある少なくとも 1 台のルータから、このネットワークが DHCPv6 で管理されている旨を表す RA を送信する必要があります。
ルータを正しく設定することができないようなネットワークをお使いの場合は、 ifcfg ファイル内のオプションで DHCLIENT6_MODE='managed' を指定することで、従来のバージョンの動作に戻すことができます。 インストールシステムを起動させる際に設定したい場合は、起動パラメータに下記の設定を追加してください:
ifcfg=eth0=dhcp6,DHCLIENT6_MODE=managed
13.6.2.7 /etc/sysconfig/network/routes および /etc/sysconfig/network/ifroute-* #Edit source
TCP/IP パケットのスタティックルーティング (固定の経路制御) に対しては、それぞれ /etc/sysconfig/network/routes ファイルと /etc/sysconfig/network/ifroute-* ファイルを使用します。さまざまなシステム処理で必要なスタティックルーティングは /etc/sysconfig/network/routes ファイル側に設定します。これにはたとえばホスト宛のルーティングのほか、ゲートウエイ経由でのルーティング、ネットワーク宛のルーティングなどを設定することができます。インターフェイス単位でルーティングを設定したい場合は、 /etc/sysconfig/network/ifroute-* (ここで、ワイルドカード ( * ) 部分にはインターフェイスの名前を入れます) ファイルを設定してください。いずれの場合も、設定ファイルの内容は下記のようになります:
# 宛先 ゲートウエイ ネットマスク インターフェイス オプション
一番左の列には宛先を記述します。ここにはネットワークやホストのアドレスのほか、 到達可能な ネームサーバが存在する場合は、完全修飾ネットワーク名もしくは完全修飾ホスト名を指定することができます。なお、ネットワークを指定する場合は、 CIDR 形式 (アドレスの後ろにプレフィクス長を付ける形式) で記述します。たとえば IPv4 であれば 10.10.0.0/16 のような形式に、 IPv6 であれば fc00::/7 のような形式になります。また、 default キーワードを指定するとデフォルトゲートウエイを指定することができます。ゲートウエイの無いデバイスの場合は、 0.0.0.0/0 もしくは ::/0 のように明示的に宛先を指定してください。
左から 2 番目の列にはゲートウエイを指定します。特定のホストやネットワーク、もしくはデフォルト (既定値) として使用するものを指定します。
左から 3 番目の列は廃止予定とされているものです。以前は IPv4 のネットマスクを指定していた箇所になります。 IPv6 の場合は一番左の列に宛先とプレフィクス長 (CIDR 形式) を指定しますので、使用していません。 IPv4 で CIDR 形式を使用している場合や、 IPv6 の場合は、ここにハイフン ( - ) を入れておいてください。
左から 4 列目にはインターフェイスの名前を指定します。ハイフン ( - ) を指定した場合は省略している意味になりますが、 /etc/sysconfig/network/routes で使用した場合は、予期しない動作になってしまう場合があります。詳しくは routes のマニュアルページをお読みください。
左から 5 列目 (オプション) には、特殊なオプション設定を記述します。詳しくは routes のマニュアルページをお読みください。
例 13.5: 一般的なネットワークインターフェイスとスタティックルーティングの設定 #
# --- CIDR 表記での IPv4 ルーティング設定: # Destination [Gateway] - Interface 127.0.0.0/8 - - lo 204.127.235.0/24 - - eth0 default 204.127.235.41 - eth0 207.68.156.51/32 207.68.145.45 - eth1 192.168.0.0/16 207.68.156.51 - eth1 # --- 古い (廃止予定の) ネットマスク形式での IPv4 ルーティング設定" # Destination [Dummy/Gateway] Netmask Interface # 127.0.0.0 0.0.0.0 255.255.255.0 lo 204.127.235.0 0.0.0.0 255.255.255.0 eth0 default 204.127.235.41 0.0.0.0 eth0 207.68.156.51 207.68.145.45 255.255.255.255 eth1 192.168.0.0 207.68.156.51 255.255.0.0 eth1 # --- IPv6 のルーティング設定 (CIDR 表記のみ使用できます): # Destination [Gateway] - Interface 2001:DB8:100::/64 - - eth0 2001:DB8:100::/32 fe80::216:3eff:fe6d:c042 - eth0
13.6.2.8 /var/run/netconfig/resolv.conf #Edit source
ホストが属するドメイン名を指定するには、 /var/run/netconfig/resolv.conf ファイル (キーワード search) を使用します。この search オプションでは、それぞれ 256 文字までのドメイン名を最大 6 つまで指定することができます。完全修飾ではない名前を解決する場合、 search で指定したドメインをそれぞれ後ろに付けて解決を行おうとします。また、このファイルでは nameserver オプションを利用して、最大 3 つまでのネームサーバを指定することができます。コメントを指定したい場合はハッシュ記号 (#) もしくはセミコロン (;) を行頭に記述します。たとえば 例13.6「/var/run/netconfig/resolv.conf」 のようになります。
なお、 /etc/resolv.conf ファイルは手作業で作成したりしないでください。このファイルは netconfig で生成されるものであるほか、 /run/netconfig/resolv.conf へのシンボリックリンクになっているためです。 YaST を利用せずに DNS の設定を行いたい場合は、 /etc/sysconfig/network/config ファイル内にある下記の項目を、手作業で編集してください:
NETCONFIG_DNS_STATIC_SEARCHLISTホスト名の参照時に使用する DNS ドメイン名のリスト
NETCONFIG_DNS_STATIC_SERVERSホスト名の参照時に使用するネームサーバの IP アドレスのリスト
NETCONFIG_DNS_FORWARDERDNS フォワーダの使用形態の指定 (例:
bindやresolverなど)NETCONFIG_DNS_RESOLVER_OPTIONS/var/run/netconfig/resolv.confに書き込むべき任意のオプション指定。例:debug attempts:1 timeout:10
詳しくは
resolv.confのマニュアルページをお読みください。NETCONFIG_DNS_RESOLVER_SORTLIST最大 10 項目まで。例:
130.155.160.0/255.255.240.0 130.155.0.0
詳しくは
resolv.confのマニュアルページをお読みください。
netconfig による DNS 設定機能を無効化したい場合は、 NETCONFIG_DNS_POLICY='' を指定してください。また、 netconfig の詳細については、 netconfig(8) のマニュアルページ ( man 8 netconfig ) をお読みください。
例 13.6: /var/run/netconfig/resolv.conf #
# ドメイン名 search example.com # # 使用するネームサーバの指定 nameserver 192.168.1.116
13.6.2.9 /sbin/netconfig #Edit source
netconfig はさまざまな追加のネットワーク設定を管理するためのモジュール型ツールです。固定で指定されている設定と DHCP や PPP などで取得した動的な設定を、あらかじめ指定したポリシーで合成したりすることができます。また、設定ファイルの修正を行う netconfig のモジュールを呼び出すことで、システムに設定を反映させることができるほか、必要なサービスを再起動したりなどの処理を行うことができます。
netconfig では、主に下記に示す 3 つのアクションを使用します。 netconfig modify や netconfig remove は DHCP や PPP などのデーモンが使用し、必要なネットワーク設定を行ったり削除したりすることができます。ユーザ側でのみ使用されるコマンドとしては、 netconfig update があります:
modifynetconfig modifyコマンドは現在のインターフェイスやサービス固有の設定を修正したり、ネットワークの設定を更新したりすることができるコマンドです。 netconfig は標準入力のほか、--lease-file ファイル名を指定すれば、ファイルから設定を読み込むこともできます。内部的には、システムの再起動を行うまで (もしくは次の modify や remove を行うまで) の範囲で保存が行われるほか、同じインターフェイスや同じサービスに対する設定が既に存在した場合、既存の設定は上書きされるようになっています。インターフェイスは-i インターフェイス名パラメータで、サービスは-s サービス名パラメータでそれぞれ指定します。removenetconfig removeコマンドは、指定したインターフェイスやサービスの組み合わせに対して、動的に編集した内容を削除してネットワーク設定を更新するコマンドです。インターフェイスは-i インターフェイス名パラメータで、サービスは-s サービス名パラメータでそれぞれ指定します。updatenetconfig updateコマンドは、現在の設定を利用してネットワークの設定を更新するためのコマンドです。これはポリシーや固定の設定を変更した場合に使用するものです。特定のサービス (例:dns,nis,ntp) のみを更新したい場合は、-m モジュール名パラメータをお使いください。
netconfig のポリシーと固定の設定は手作業で設定することができるほか、 YaST で設定することもできます。いずれも /etc/sysconfig/network/config ファイルを編集することになります。 DHCP や PPP など自動設定ツールで提供される動的な設定は、それぞれ netconfig modify や netconfig remove のコマンドを介して動的に配信されます。 NetworkManager が有効化されている場合は、 netconfig (ポリシーモードが auto である場合) は NetworkManager 側の設定のみを使用し、従来の ifup 方式を利用したインターフェイスの設定は無視されるようになります。 NetworkManager が何も設定を提供しない場合は、代替として固定の設定を使用します。 NetworkManager と wicked を混在させて使用することはできません (サポートしていません)。
netconfig に関する詳細は、 man 8 netconfig をお読みください。
13.6.2.10 /etc/hosts #Edit source
例13.7「/etc/hosts」 に示しているとおり、このファイルには IP アドレスとそれに対応するホスト名を記述します。ネットワーク内にネームサーバが存在していない場合、 IP で接続する全てのホストをここに記述する必要があります。各行には IP アドレスと完全修飾ホスト名、およびホスト名単体をそれぞれ指定します。なお、 IP アドレスは行頭に配置しなければならず、各項目の間はスペースもしくはタブで区切ります。コメントを記述したい場合は、行頭に # 記号を入力します。
例 13.7: /etc/hosts #
127.0.0.1 localhost 192.168.2.100 jupiter.example.com jupiter 192.168.2.101 venus.example.com venus
13.6.2.11 /etc/networks #Edit source
ここでは、ネットワーク名とネットワークアドレスを記述します。書式は hosts と同様ですが、ネットワーク名のほうを左側に記述します。詳しくは 例13.8「/etc/networks」 をご覧ください。
例 13.8: /etc/networks #
loopback 127.0.0.0 localnet 192.168.0.0
13.6.2.12 /etc/host.conf #Edit source
このファイルでは、ホスト名やネットワーク名を解決する リゾルバ ライブラリの制御を行います。このファイルは libc4 や libc5 とリンクされているプログラムのみが使用します。現行の glibc プログラムの場合は /etc/nsswitch.conf ファイルで設定を行います。このファイルでは、それぞれのパラメータは別々の行に記述します。コメントは行頭に # を入力します。 表13.2「/etc/host.conf で使用するパラメータ」 には、利用可能なパラメータの一覧が示されています。また、 /etc/host.conf の設定例は 例13.9「/etc/host.conf」 にあります。
表 13.2: /etc/host.conf で使用するパラメータ #
|
order hosts , bind |
名前解決の際のサービスの利用順序を指定します。指定可能な値は下記のとおりです (複数のものを指定する場合は、スペースもしくはカンマで区切ります): |
|
hosts : | |
|
bind : ネームサーバにアクセスを行います | |
|
nis : NIS を使用します | |
|
multi on / off |
|
|
nospoof on spoofalert on / off |
これらのパラメータは、ネームサーバの なりすまし に対する設定を表しますが、ネットワークの設定に対しては特に影響がありません。 |
|
trim ドメイン名 |
ホスト名の解決を行ったあと、ホスト名に指定したドメイン名が含まれていれば、そのドメイン名部分を分離する指定です。このオプションは、 |
例 13.9: /etc/host.conf #
# ネームサーバが存在する order hosts bind # 複数アドレスの許可 multi on
13.6.2.13 /etc/nsswitch.conf #Edit source
GNU C Library 2.0 およびそれ以降のバージョンでは、 Name Service Switch (NSS) と呼ばれる仕組みが導入されています。詳細については nsswitch.conf(5) のマニュアルページ、もしくは The GNU C Library Reference Manual (GNU C ライブラリリファレンスマニュアル) をお読みください。
問い合わせの順序は /etc/nsswitch.conf ファイルで設定します。 nsswitch.conf の設定例については 例13.10「/etc/nsswitch.conf」 をご覧ください。コメントは行頭に # を入力します。この例の hosts では、 /etc/hosts ( files ) に問い合わせたのち、 DNS (詳しくは第19章 「ドメインネームシステム」 をお読みください) に問い合わせを行います。
例 13.10: /etc/nsswitch.conf #
passwd: compat group: compat hosts: files dns networks: files dns services: db files protocols: db files rpc: files ethers: files netmasks: files netgroup: files nis publickey: files bootparams: files automount: files nis aliases: files nis shadow: compat
NSS で利用可能な 「データベース」 の一覧は 表13.3「/etc/nsswitch.conf で使用できるデータベース」 に示されています。また、 NSS データベースで設定可能なオプションの一覧は、 表13.4「NSS 「データベース」 での設定オプション」 に示されています。
表 13.3: /etc/nsswitch.conf で使用できるデータベース #
|
|
|
|
|
イーサネットアドレス。 |
|
|
ネットワークとそれらのサブネットマスク。サブネットを設定する場合にのみ使用します。 |
|
|
|
|
|
|
|
|
アクセス権を制御するためのネットワーク内のホストとユーザのリスト。詳しくは |
|
|
|
|
|
NFS および NIS+ で使用される Secure_RPC 向けの公開鍵と機密鍵。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表 13.4: NSS 「データベース」 での設定オプション #
|
|
|
|
|
データベース経由でのアクセス |
|
|
NIS (詳しくは 第3章 「NIS の使用」 をお読みください) |
|
|
|
|
|
|
13.6.2.14 /etc/nscd.conf #Edit source
このファイルは nscd (ネームサービスキャッシュデーモン; name service cache daemon) を設定するために使用するものです。詳しくは nscd(8) や nscd.conf(5) のマニュアルページをお読みください。既定では、 passwd , groups , hosts の各システム項目がキャッシュ対象となります。これは NIS や LDAP などのディレクトリサービスの性能を確保するためには重要な設定となります。キャッシュを使用しないと、名前やグループ、ホストにアクセスがあるごとにネットワークへの接続が発生することになってしまうためです。
passwd に対するキャッシュ機能を有効化した場合、新しくローカルユーザを追加した場合は、それが反映されるまでに 15 秒程度の時間がかかります。この待機を行いたくない場合は、下記のようにして nscd を再起動してください:
>sudosystemctl restart nscd
13.6.2.15 /etc/hostname #Edit source
/etc/hostname には完全修飾ホスト名 (FQHN) が含まれています。完全修飾ホスト名とはホスト名にドメイン名が付加されたものを意味しています。このファイルには、設定したい完全修飾ホスト名を 1 行だけ記述してください。また、このファイルはマシンの起動時に読み込まれます。
13.6.3 設定のテスト #Edit source
設定ファイル内に独自の設定を行う前に、事前にテストを行っておくことをお勧めします。テスト設定を行うには ip コマンドを、接続をテストするには ping コマンドを使用します。
ip コマンドは、設定ファイルに設定を保存することなく、ネットワークの設定を直接変更します。そのため、変更した設定はシステムを再起動したり仮想アダプタのリセットをしたりすると、元に戻ってしまいます。
注記: ifconfig と route の廃止予定について
ifconfig と route の各ツールは、廃止予定としてマークされています。代わりに ip コマンドをお使いください。また、 ifconfig コマンドは、インターフェイス名の長さが 9 文字までに制限されています。
13.6.3.1 ip を利用したネットワークインターフェイスの設定 #Edit source
ip コマンドは、ネットワークデバイスやルーティング、ポリシールーティングやトンネルなどを設定したり、設定を取得したりするためのツールです。
ip コマンドは非常に複雑なツールです。一般的には ip オプション オブジェクト コマンド の形式で実行します。オブジェクトには下記のものがあります:
- link
このオブジェクトは、ネットワークデバイスそのものを表します。
- address
このオブジェクトは、デバイスの IP アドレスを表します。
- neighbor
このオブジェクトは、 ARP や NDISC のキャッシュ項目などを表します。
- route
このオブジェクトは、ルーティングテーブルの項目を表します。
- rule
このオブジェクトは、ルーティングポリシーデータベース内のルールを表します。
- maddress
このオブジェクトは、マルチキャストのアドレスを表します。
- mroute
このオブジェクトは、マルチキャストのルーティングキャッシュ項目を表します。
- tunnel
このオブジェクトは、 IP 経由でのトンネルを表します。
何もコマンドを指定しない場合は、指定のコマンド (通常は list) が指定されているものと見なします。
デバイスの状態を変更するには、下記のコマンドを実行します:
>sudoip link set デバイス名
たとえばデバイス eth0 を無効化したい場合は、下記のように入力して実行します:
>sudoip link set eth0 down
有効化したい場合は、下記のように入力して実行します:
>sudoip link set eth0 up
ヒント: NIC デバイスの切断について
デバイスを無効化するには、下記のように入力して実行します:
>sudoip link set デバイス名 down
ただし、このコマンドはネットワークインターフェイスをソフトウエアレベルで無効化するだけです。
イーサネットケーブルが取り外された場合や、スイッチの電源が切れた場合のように、リンクを失った場合の処理を行わせたい場合は、下記のように入力して実行します:
>sudoip link set デバイス名 carrier off
なお、 ip link set デバイス名 down は デバイス名 を経由する全ての経路 (ルーティング) 情報を削除しますが、 ip link set デバイス名 carrier off ではそのようなことは行いません。また carrier off コマンドは、対応するネットワークデバイスのドライバ側での対応が必要となります。
デバイスに対する物理的な接続を復帰させるには、下記のように入力して実行します:
>sudoip link set デバイス名 carrier on
デバイスを有効化したあとは、様々な設定作業を行うことができます。 IP アドレスを設定するには、下記のように入力して実行します:
>sudoip addr add IP_アドレス + dev デバイス名
たとえば標準ブロードキャストオプション (オプション brd) を指定して、インターフェイス eth0 に 192.168.12.154/30 というアドレスを設定するには、下記のように入力して実行します:
>sudoip addr add 192.168.12.154/30 brd + dev eth0
ネットワーク接続を正しく動作させるには、通常はデフォルトゲートウエイの設定も行わなくてはなりません。お使いのシステムにデフォルトゲートウエイを設定するには、下記のようなコマンドを入力して実行します:
>sudoip route add default via デフォルトゲートウエイの_IP_アドレス
全てのデバイスを一覧表示するには、下記のように入力して実行します:
>sudoip link ls
動作中のインターフェイスのみを表示したい場合は、下記のように入力して実行します:
>sudoip link ls up
特定のデバイスに対する統計情報を表示するには、下記のように入力して実行します:
>sudoip -s link ls デバイス名
仮想ネットワークデバイスなどの追加情報を表示するには、下記のように入力して実行します:
>sudoip -d link ls デバイス名
上記に加えてデバイスに設定されたネットワーク層 (IPv4, IPv6) のアドレスも表示したい場合は、下記のように入力して実行します:
>sudoip addr
上記の出力には、各デバイスの MAC アドレスに関する情報も表示されます。また、全ての経路 (ルーティング) 情報を表示するには、下記のように入力して実行します:
>sudoip route show
ip コマンドの使用方法について、詳しくは ip help を実行すると表示されるヘルプ、もしくは man 8 ip コマンドで表示されるマニュアルページをお読みください。このほか、 ip コマンドのサブコマンドの後ろに help オプションを指定することもできます。たとえば下記のように入力して実行することができます:
>sudoip addr help
それ以外にも、 /usr/share/doc/packages/iproute2/ip-cref.pdf ファイルには ip コマンドのマニュアルも用意されています。
13.6.3.2 ping による通信テスト #Edit source
ping コマンドは、 TCP/IP の接続が動作しているかどうかをテストすることができる標準的なツールです。このツールは ICMP プロトコルを利用して、 ECHO_REQUEST データグラムと呼ばれる小さなデータパケットを宛先のホストに送信し、相手側からの即時の応答を待ちます。応答があると、 ping はその旨を示すメッセージを表示します。これにより、ネットワークが正しく動作していることを確認することができます。
ping は 2 台のコンピュータ間での接続機能テストを行うだけではありません。基本的な接続品質に関する情報も提供します。 例13.11「ping コマンドの出力」 には ping の出力例を示していますが、出力の末尾から 2 行目には、送信したパケット数と損失数、および ping の実行にかかった時間が表示されます。
また、宛先の指定には IP アドレスだけでなくホスト名を指定することもできます。たとえばping example.com や ping 192.168.3.100 のように実行することができます。また、このプログラムは Ctrl–C を押すまでパケットを送り続けます。
接続ができるかどうかだけを調べたい場合は、 -c オプションでパケットの送信回数を制限してください。たとえば 3 回パケットを送信したい場合は、ping -c 3 example.com のように入力して実行します。
例 13.11: ping コマンドの出力 #
ping -c 3 example.com PING example.com (192.168.3.100) 56(84) bytes of data. 64 bytes from example.com (192.168.3.100): icmp_seq=1 ttl=49 time=188 ms 64 bytes from example.com (192.168.3.100): icmp_seq=2 ttl=49 time=184 ms 64 bytes from example.com (192.168.3.100): icmp_seq=3 ttl=49 time=183 ms --- example.com ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2007ms rtt min/avg/max/mdev = 183.417/185.447/188.259/2.052 ms
既定の送信間隔は 1 秒に設定されています。この間隔を変更したい場合は、 -i オプションを指定してください。たとえば送信間隔を 10 秒にしたい場合は、 ping -i 10 example.com のように入力して実行します。
なお、システムに複数のネットワークデバイスが存在する場合は、インターフェイスを指定して送信したほうが便利である場合があります。これを行うには、 -I とデバイス名を指定してください。たとえば ping -I wlan1 example.com のように入力して実行します。
ping の使用方法について、詳しくは ping -h で表示されるヘルプ、もしくは ping (8) のマニュアルページをお読みください。
ヒント: IPv6 アドレスへの ping
IPv6 アドレスの場合は、 ping6 コマンドを使用します。ただし、リンクローカルアドレスに対して送信したい場合は、 -I でインターフェイス名を指定してください。たとえば下記のコマンドが成功した場合は、 eth1 を介して指定したアドレスに到達できる意味になります:
ping6 -I eth1 fe80::117:21ff:feda:a425
13.6.4 ユニットファイルと起動スクリプト #Edit source
上述までの設定のほかに、マシンを起動する際にネットワークサービスを読み込むための systemd ユニットファイルと各種スクリプトが存在しています。これらはシステムが multi-user.target ターゲットに切り替わる際に開始されます。これらのユニットファイルやスクリプトファイルのいくつかは、 ネットワークプログラム向けのユニットファイルと起動スクリプト で説明しています。なお、 systemd についての詳細は、 第10章 「systemd デーモン」 をお読みください。また、 systemd のターゲットに関する詳細は、 systemd.special のマニュアルページ ( man systemd.special ) をお読みください。
ネットワークプログラム向けのユニットファイルと起動スクリプト #
network.targetnetwork.targetはネットワーク処理のための systemd ターゲットですが、この意味合いはシステム管理者が設定した内容によって異なります。詳しくは https://www.freedesktop.org/wiki/Software/systemd/NetworkTarget/ をお読みください。
multi-user.targetmulti-user.targetは systemd ターゲットのうちの 1 つで、全てのネットワークサービスを有効化したマルチユーザシステムを開始するためのものです。rpcbindRPC のプログラム番号をユニバーサルアドレスに変換する
rpcbindユーティリティを起動します。 NFS サーバなどで必要となります。ypservNIS サーバを開始します。
ypbindNIS クライアントを開始します。
/etc/init.d/nfsserverNFS サーバを開始します。
/etc/init.d/postfixpostfix プロセスを制御します。
13.7 基本的なルータの構築 #Edit source
ルータとはネットワークデバイスの一種で、一方のインターフェイスからデータ (ネットワークパケット) を受信して、他方 (複数の場合もある) に送信して中継する機器です。ルータはローカルのネットワークからリモートのネットワーク (インターネット) に接続する際に一般的に使用されているほか、ローカルのネットワーク同士を接続する場合にも用いられることがあります。 openSUSE Leap でも、 NAT (ネットワークアドレス変換; Network Address Translation) や高度なファイアウオール機能の付属したルータを構築することができます。
openSUSE Leap をルータにするには、下記の基本的な手順を踏む必要があります。
まずはパケットの転送機能を有効化します。たとえば
/etc/sysctl.d/50-router.conf内で下記のように設定します:net.ipv4.conf.all.forwarding = 1 net.ipv6.conf.all.forwarding = 1
あとはそれぞれのインターフェイスに対して、 IPv4 と IPv6 の固定アドレスを設定します。パケットの転送機能を有効化すると、 IPv6 の RA (ルータ告知; Router Advertisement) などのいくつかの仕組みが無効化され、既定のルートも自動では設定されなくなります。
多くの場合 (たとえば複数のインターフェイスを介して同じネットワークに到達できるような場合や、 VPN を一般的に使用している 「一般的なマルチホームホスト」 の場合など) において、 IPv4 のリバースパスフィルタを無効化しなければなりません (この機能は、 IPv6 では現在存在していません):
net.ipv4.conf.all.rp_filter = 0
ファイアウオールの設定でフィルタすることもできます。
外部やアップリンク、 ISP などから IPv6 RA を受け付けて、 IPv6 のデフォルトルートを作成するようにするには、下記のように設定します:
net.ipv6.conf.${ifname}.accept_ra = 2 net.ipv6.conf.${ifname}.autoconf = 0(注意: 「
eth0.42」 のようなインターフェイスの場合は、eth0/42のように sysfs パス形式で記述する必要があります)
さらなるルータの動作に転送ポリシーなどについて、詳しくは https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt をお読みください。
IPv6 を内部 (もしくは DMZ) インターフェイスに提供し、自分自身を IPv6 ルータとして動作させて 「autoconf ネットワーク」 を提供するには、 radvd をインストールして /etc/radvd.conf を下記のように設定する必要があります:
interface eth0
{
IgnoreIfMissing on; # インターフェイスが存在していなくてもエラーにしない
AdvSendAdvert on; # RA の送信の有効化
AdvManagedFlag on; # DHCPv6 での IPv6 アドレスの管理
AdvOtherConfigFlag on; # DNS, NTP などは DHCPv6 のみ
AdvDefaultLifetime 3600; # クライアント側でのデフォルトルートの有効期間 (1 時間)
prefix 2001:db8:0:1::/64 # (/64 は既定値であり、 autoconf でも必要となる)
{
AdvAutonomous off; # アドレス autoconf の無効化 (DHCPv6 のみ)
AdvValidLifetime 3600; # プレフィクス (autoconf アドレス) の有効期間 (1 時間)
AdvPreferredLifetime 1800; # プレフィクス (autoconf アドレス) の更新期間はその半分 (30 分)
}
}また、 NAT を利用して LAN から WAN にパケットを転送し、それと共にアドレス変換を行い、さらに WAN 側からの入力パケットをブロックしたい場合は、下記のように実行します:
>sudofirewall-cmd--permanent --zone=external --change-interface=WAN_インターフェイス>sudofirewall-cmd--permanent --zone=external --add-masquerade>sudofirewall-cmd--permanent --zone=internal --change-interface=LAN_インターフェイス>sudofirewall-cmd--reload
13.8 ボンドデバイスの設定 #Edit source
システムによっては、一般的なイーサネットデバイスにおける標準的なセキュリティや可用性の要件を越えて、ネットワーク接続を実装する要望がある場合があります。このような場合は、複数のイーサネットデバイスをまとめて、 1 つのボンドデバイスにすることができます。
ボンドデバイスの設定はボンドモジュールを設定して行います。また、このモジュールの動作はモードによって切り替えることができます。既定では active-backup (アクティブ-バックアップ) モードに設定されていて、一方のデバイスに障害が発生した場合に、他方のデバイスに切り替える動作を行います。モードには下記の設定が用意されています:
- (balance-rr)
パケットはラウンドロビン形式で、最初のインターフェイスから最後のインターフェイスまで、パケットを 1 つずつ送りながらインターフェイスを切り替える動作になります。これにより、冗長化と負荷分散の両方を実現することができます。
- (active-backup)
いずれか 1 つのネットワークインターフェイスのみを有効に設定します。そのネットワークインターフェイスに障害が発生すると、異なるインターフェイスが有効化されます。この設定は openSUSE Leap における既定値で、冗長化のみを実現することができます。
- (balance-xor)
パケットはボンド内に含まれているデバイス数を基準に、利用可能な全てのインターフェイスに分散されます。接続するスイッチ側での対応が必要です。冗長化と負荷分散の両方を提供します。
- (broadcast)
全てのパケットを全てのインターフェイスに送信します。接続するスイッチ側での対応が必要です。冗長化のみを実現することができます。
- (802.3ad)
同じ速度と二重通信方式を共有する複数のインターフェイスを、 1 つにまとめる設定です。インターフェイスドライバ側に
ethtoolのサポートが必要となるほか、接続するスイッチ側で IEEE 802.3ad 動的リンク集約の設定を行う必要があります。冗長化と負荷分散の両方を提供します。- (balance-tlb)
順応型送信負荷分散を行います。インターフェイスドライバ側に
ethtoolのサポートが必要となりますが、スイッチ側での対応は不要です。冗長化と負荷分散の両方を提供します。- (balance-alb)
順応型負荷分散を行います。インターフェイスドライバ側に
ethtoolのサポートが必要となりますが、スイッチ側での対応は不要です。冗長化と負荷分散の両方を提供します。
モードに関する詳細な説明については、 https://www.kernel.org/doc/Documentation/networking/bonding.txt をお読みください。
ヒント: ボンドと Xen
ボンドデバイスの使用は、複数のネットワークカードを接続しているマシンでのみ設定することができる仕様です。ほとんどの設定において、ボンドデバイスは Dom0 でのみ使用すべきものであることを意味します。 VM ゲスト システムに対して複数のネットワークカードを割り当てている場合にのみ、 VM ゲスト 内でボンディングを設定することができることになります。
ボンドデバイスを設定するには、下記の手順で行います:
› › を実行します。
を押し、 に を選択して、 を押します。
ボンドデバイスへの IP アドレスの割り当て方法を指定します。下記の 3 種類の中から選択します:
IP の設定無し
可変 IP アドレス (DHCP もしくは Zeroconf)
固定 IP アドレス
お使いの環境に適切なものを選択してください。
また、 のタブでは、ボンドデバイスに含めるべきインターフェイスを、チェックボックスで選択します。
を編集して、モードを設定します。
なお、 の末尾に
miimon=100のパラメータが存在していることを確認してください。このパラメータを指定しないと、定期的なチェックが行われなくなります。を押して進み、 を押して YaST を終了すると、デバイスを作成することができます。
13.8.1 ボンドポートのホットプラグ #Edit source
ネットワーク環境 (たとえば高可用性が必要な環境) によっては、障害の発生したネットワークインターフェイスを別のものに交換する必要がある場合があります。このような要件を満たすには、ボンドポートのホットプラグを設定して解決する必要があります。
ボンドの設定を通常通りに行います (詳しくは man 5 ifcfg-bonding をお読みください) 。たとえば下記のようになります:
ifcfg-bond0
STARTMODE='auto' # or 'onboot'
BOOTPROTO='static'
IPADDR='192.168.0.1/24'
BONDING_MASTER='yes'
BONDING_SLAVE_0='eth0'
BONDING_SLAVE_1='eth1'
BONDING_MODULE_OPTS='mode=active-backup miimon=100'ボンドポート側には STARTMODE=hotplug と BOOTPROTO=none を指定します:
ifcfg-eth0
STARTMODE='hotplug'
BOOTPROTO='none'
ifcfg-eth1
STARTMODE='hotplug'
BOOTPROTO='none'BOOTPROTO=none を指定すると、 ethtool を使用して設定が行われますが、 ifup eth0 で起動が行われなくなります。これはボンドポートのインターフェイスはボンドデバイス側で制御されるべきであるためです。
STARTMODE=hotplug を指定すると、ボンドポートインターフェイスが利用可能な状態になった際に、自動的にボンドデバイスに参加するようになります。
また、 /etc/udev/rules.d/70-persistent-net.rules 内にある udev のルールを、 MAC アドレスではなくバス ID を指定する形式に変更する必要があります (udev の KERNELS キーに、 hwinfo --netcard で出力される "SysFS のバス ID"を指定します) 。これにより、障害の発生したハードウエア (同じスロットにありながら、 MAC アドレスの異なるハードウエア) を交換することができるようになり、 MAC アドレスが変更されることによるボンドドライバ側の問題を回避できるようになります。
たとえば下記のようになります:
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*",
KERNELS=="0000:00:19.0", ATTR{dev_id}=="0x0", ATTR{type}=="1",
KERNEL=="eth*", NAME="eth0"システムの起動時点では、 systemd の network.service はホットプラグ指定されたボンドポートを待機しませんが、ボンドインターフェイスを動作させるためには、少なくとも 1 つ以上のボンドポートが必要となります。ボンドポートのいずれかが取り外される (NIC ドライバからバインド解除される、つまり NIC のドライバが rmmod されるか、 PCI ホットプラグで取り外される) と、カーネルはボンドデバイスについても自動的に削除を行います。新しいカードがシステムに接続される (置き換えとして同じスロットに接続される) と、 udev はバス ID ベースの固定名を付与して ifup を呼び出します。 ifup 側では、ボンドデバイス側への参加を自動的に行います。
13.8.2 予測可能なインターフェイス命名方式 #Edit source
ネットワークインターフェイスに対して恒久的な名前を設定する機能とボンディングを併用しようとすると問題が発生します。これは、インターフェイスがボンドデバイスに参加する際、 MAC アドレスはボンドデバイスのものに一時的に上書きされるため、 70-persistent-net.rules において MAC アドレスベースの命名を行っている場合、うまく動作しなくなってしまうためです。
なお、 MAC アドレス変更済みの NIC に対して uevent が実行された場合、 udev は暫定的なインターフェイス名 (例: rename4) を設定します。また、 MAC アドレスベースのルールを避けて別の方式で恒久的な名前を設定しようとするのも現実的ではありません。このような事情から、恒久的な命名方式は廃止予定とされ、新たに予測可能な命名方式に置き換えられるようになっています。これにより設定の可能性が広がっているほか、 MAC アドレスにも依存しなくなっています。予測可能な命名方式は、新規システムのインストール時に 起動オプション に net.ifnames=1 を設定することで有効化できます。
手順 13.1: インストール済みのシステムにおける命名方式の有効化 #
biosdevname パッケージがインストールされている場合、アンインストールします。
>sudozypper rm biosdevname/etc/udev/rules.d内に既存の命名方式が設定されている場合は、まずバックアップしておきます。たとえば下記のように実行します:>sudocp /etc/udev/rules.d/70-persistent-net.rules /backup注記
/etc/udev/rules.d/70-persistent-net.rules内の既存の命名方式があれば、これらを削除して予測可能なインターフェイス命名方式に切り替えます。initrd を生成し直します。
>sudodracut -fあとは YaST ブートローダモジュールを起動して、カーネルのコマンドラインに
net.ifnames=1を追加します。作業が終わったら を押してシステムを再起動してください。なお、 Wicked をネットワークマネージャとして使用している場合は、ネットワークインターフェイスの設定も変更しておく必要があります。
yast lanモジュールを実行して設定し直すか、もしくは/etc/sysconfig/network/ifcfg-*のファイル名を変更してください。ファイル名を変更したあとは、下記のようにして Wicked を再起動してください。>sudosystemctl restart wicked.service
13.9 ネットワークチーミング によるチームデバイス (チーミング/ボンディング) の設定 #Edit source
「リンクアグリゲーション」 とは、複数のネットワーク接続を組み合わせて (もしくは束ねて) 1 つの論理レイヤを提供する一般的な用語です。これは 「チャンネルチーミング」 , 「イーサネットボンディング」 , 「ポートトランキング」 などと呼ばれることもありますが、いずれも同じような意味であり、同じような意図で作られている仕組みです。
これらの考え方は一般に 「ボンディング」 として知られているもので、元々は Linux カーネル内に組み込まれている機能を意味します (ボンディングについての詳細は、 13.8項 「ボンドデバイスの設定」 をお読みください) 。 ネットワークチーミング という用語は、この考え方をさらに進化させた実装を意味しています。
ボンディングと ネットワークチーミング の大きな違いとして挙げられるのは、チーミングは teamd のインスタンスに対してインターフェイスを提供するための小さなカーネルモジュールが複数存在するという点です。それ以外の処理は全てユーザスペース側で行います。ボンディングはこれとは異なり、全ての機能をカーネル側で行っています。詳しい比較については、 表13.5「ボンディングとチーミングの機能比較」 をお読みください。
表 13.5: ボンディングとチーミングの機能比較 #
| 機能 | ボンディング | チーミング |
|---|---|---|
| ブロードキャスト型/ラウンドロビン型送信ポリシー | はい | はい |
| アクティブ-バックアップ型送信ポリシー | はい | はい |
| LACP (802.3ad) サポート | はい | はい |
| ハッシュベースの送信ポリシー | はい | はい |
| ユーザ側でのハッシュ関数の設定 | いいえ | はい |
| 送信負荷分散 (TLB) サポート | はい | はい |
| LACP 向けの送信負荷分散サポート | いいえ | はい |
| ethtool リンク監視 | はい | はい |
| ARP リンク監視 | はい | はい |
| NS/NA (IPV6) リンク監視 | いいえ | はい |
| TX/RX パスにおける RCU ロッキング | いいえ | はい |
| ポートの優先順位と固着設定 | いいえ | はい |
| 個別/ポート別リンク監視設定 | いいえ | はい |
| 複数リンクの監視設定 | 制限あり | はい |
| VLAN サポート | はい | はい |
| 複数デバイスのスタック | はい | はい |
| 情報源: https://libteam.org/files/teamdev.pp.pdf | ||
ボンディングと ネットワークチーミング の実装は、同時に使用することもできます。また、 ネットワークチーミング は既存のボンディングに対する代替としても使用することができますが、置き換えるようなものではありません。
ネットワークチーミング には様々な用途があります。本章では下記にある最も重要な 2 つの用途を説明しています:
異なるネットワークデバイス間の負荷分散
デバイスに障害が発生した場合の、一方から他方へのネットワークデバイスの切り替え
現時点では、チーミングデバイスを作成するための YaST モジュールは用意されていません。 ネットワークチーミング をご利用になる場合は、手作業で設定を行う必要があります。なお、下記には全ての ネットワークチーミング 設定で利用することのできる、一般的な手順を説明しています:
手順 13.2: 一般的な手順 #
まずは libteam-tools パッケージをインストールします:
>sudozypper in libteam-tools次に
/etc/sysconfig/network/ディレクトリ内に設定ファイルを作成します。一般的にはifcfg-team0のようなファイル名で作成します。複数の ネットワークチーミング デバイスを作成する場合は、末尾の数字を 1 つずつ増やしながら作成してください。この設定ファイルには、マニュアルページで説明されている各種の指定を記述します。詳しくは
man ifcfgおよびman ifcfg-teamをお読みください。また、お使いのシステム内には、設定ファイルのサンプル (/etc/sysconfig/network/ifcfg.template) も用意されていますので、こちらもあわせてお読みください。チーミングデバイス内に組み込むインターフェイスの設定ファイルを削除します。たとえば
ifcfg-eth0やifcfg-eth1などを削除してください。なお、いずれのファイルとも、バックアップを取ってから削除することをお勧めします。 Wicked 側では、チーミングに必要なパラメータで設定ファイルを再作成します。
なお、必要であれば Wicked の設定ファイルとして取り込まれていることを確認します:
>sudowicked show-configネットワークチーミング デバイス
team0を開始するため、下記のコマンドを実行します:>sudowicked ifup team0デバッグ情報を取得する必要がある場合は、
allサブコマンドの後ろに--debug allを指定してください。ネットワークチーミング デバイスの状態を確認します。具体的には下記のコマンドを実行します:
まずは Wicked の teamd インスタンスの状態を確認します:
>sudowicked ifstatus --verbose team0インスタンス全体の状態を確認します:
>sudoteamdctl team0 stateteamd インスタンスの systemd の状態を確認します:
>sudosystemctl status teamd@team0
それぞれは、お使いの環境によって出力が少しずつ異なります。
何らかの理由で
ifcfg-team0を書き換える必要がある場合は、書き換えた後に下記のコマンドを実行して、設定ファイルを再読み込みさせてください:>sudowicked ifreload team0
ただし、チーミングデバイスの開始や停止に際しては、 systemctl を 使用しないでください 。代わりに、上述のとおり wicked コマンドを使用してください。
チーミングデバイスを削除するには、下記の手順で行います:
手順 13.3: チーミングデバイスの削除 #
まずは ネットワークチーミング デバイス (例:
team0) を停止します:>sudowicked ifdown team0設定ファイル
/etc/sysconfig/network/ifcfg-team0を/etc/sysconfig/network/.ifcfg-team0のように名前変更します。ファイル名の冒頭にドットを入れることで、 wicked からは読み込みができなくなります。完全に不要になった段階で、ファイルを削除してください。設定を再読み込みします:
>sudowicked ifreload all
13.9.1 使用例: ネットワークチーミング による負荷分散 #Edit source
負荷分散は帯域を増やすための仕組みです。下記のような設定で ネットワークチーミング デバイスを作成すると、負荷分散の機能を設定することができます。デバイスの開始や停止、設定ファイルの配置などについては、 手順13.2「一般的な手順」 をお読みください。また、設定後は teamdctl の出力もご確認ください。
例 13.12: ネットワークチーミング による負荷分散の設定例 #
STARTMODE=auto 1 BOOTPROTO=static 2 IPADDRESS="192.168.1.1/24" 2 IPADDR6="fd00:deca:fbad:50::1/64" 2 TEAM_RUNNER="loadbalance" 3 TEAM_LB_TX_HASH="ipv4,ipv6,eth,vlan" TEAM_LB_TX_BALANCER_NAME="basic" TEAM_LB_TX_BALANCER_INTERVAL="100" TEAM_PORT_DEVICE_0="eth0" 4 TEAM_PORT_DEVICE_1="eth1" 4 TEAM_LW_NAME="ethtool" 5 TEAM_LW_ETHTOOL_DELAY_UP="10" 6 TEAM_LW_ETHTOOL_DELAY_DOWN="10" 6
チーミングデバイスの開始方法を制御しています。 デバイスを自動起動せず、手動で起動する必要がある場合は、 | |
固定の IP アドレスを設定しています (ここでは IPv4 アドレスとして ネットワークチーミング デバイスで動的な IP アドレスを使用する場合は、 | |
| |
ネットワークチーミング デバイスを構成する 1 つ以上のデバイスを指定しています。 | |
従属するデバイスの状態を開始するためのリンク監視機構を定義しています。既定値の この接続の信頼性を高めたい場合は、 | |
リンクが確立し (もしくはリンクが外れ) てから、リンク監視機構がそれを確認するまでの時間をミリ秒単位で指定します。 |
13.9.2 使用例: ネットワークチーミング による冗長構成 #Edit source
冗長構成は ネットワークチーミング デバイスで高可用性を実現するための仕組みで、予備のネットワークデバイスを用意して障害に耐える仕組みを作るものです。予備のネットワークデバイスは常に動作し続け、メインのデバイスに障害が発生すると通信を引き継ぐようになります。
下記のような設定で ネットワークチーミング デバイスを作成すると、冗長構成の機能を設定することができます。デバイスの開始や停止、設定ファイルの配置などについては、 手順13.2「一般的な手順」 をお読みください。また、設定後は teamdctl の出力もご確認ください。
例 13.13: ネットワークチーミング デバイスに対する冗長構成 の設定例 #
STARTMODE=auto 1 BOOTPROTO=static 2 IPADDR="192.168.1.2/24" 2 IPADDR6="fd00:deca:fbad:50::2/64" 2 TEAM_RUNNER=activebackup 3 TEAM_PORT_DEVICE_0="eth0" 4 TEAM_PORT_DEVICE_1="eth1" 4 TEAM_LW_NAME=ethtool 5 TEAM_LW_ETHTOOL_DELAY_UP="10" 6 TEAM_LW_ETHTOOL_DELAY_DOWN="10" 6
チーミングデバイスの開始方法を制御しています。 デバイスを自動起動せず、手動で起動する必要がある場合は、 | |
固定の IP アドレスを設定しています (ここでは IPv4 アドレスとして ネットワークチーミング デバイスで動的な IP アドレスを使用する場合は、 | |
| |
ネットワークチーミング デバイスを構成する 1 つ以上のデバイスを指定しています。 | |
従属するデバイスの状態を開始するためのリンク監視機構を定義しています。既定値の この接続の信頼性を高めたい場合は、 | |
リンクが確立し (もしくはリンクが外れ) てから、リンク監視機構がそれを確認するまでの時間をミリ秒単位で指定します。 |
13.9.3 使用例: チーミングデバイスでの VLAN #Edit source
VLAN とは 仮想ローカルエリアネットワーク (Virtual Local Area Network) の略で、複数の 論理 イーサネットを単一の物理イーサネットで賄う仕組みです。この仕組みにより、 1 つのネットワークを複数の異なるネットワークに分割して、スイッチ側では同じ VLAN 同士の通信のみを中継するような動作を実現することができます。
下記の使用例では、チーミングデバイスから 2 つの固定 VLAN を作成します:
vlan0: IP アドレス=192.168.10.1vlan1: IP アドレス=192.168.20.1
下記の手順で行います:
まずはスイッチ側で VLAN タグ機能を有効化します。また、チーミングデバイスで負荷分散を実施している場合は、 Link Aggregation Control Protocol (LACP) (802.3ad) に対応したスイッチでなければなりません。詳しくはハードウエアのマニュアルをお読みください。
次にチーミングデバイスで負荷分散や冗長構成を使用するかどうかを決めます。それぞれの設定を行うには、 13.9.1項 「使用例: ネットワークチーミング による負荷分散」 や 13.9.2項 「使用例: ネットワークチーミング による冗長構成」 をお読みください。
/etc/sysconfig/networkディレクトリ内にifcfg-vlan0という設定ファイルを作成し、下記の内容を記述します:STARTMODE="auto" BOOTPROTO="static" 1 IPADDR='192.168.10.1/24' 2 ETHERDEVICE="team0" 3 VLAN_ID="0" 4 VLAN='yes'
設定ファイル
/etc/sysconfig/network/ifcfg-vlan0を/etc/sysconfig/network/ifcfg-vlan1にコピーして、コピーした先のファイルを下記のとおり変更します:IPADDRの値を192.168.10.1/24から192.168.20.1/24に変更します。VLAN_IDを0から1に変更します。
あとは 2 つの VLAN を開始します:
#wickedifup vlan0 vlan1ifconfigの出力を確認します:#ifconfig-a [...] vlan0 Link encap:Ethernet HWaddr 08:00:27:DC:43:98 inet addr:192.168.10.1 Bcast:192.168.10.255 Mask:255.255.255.0 inet6 addr: fe80::a00:27ff:fedc:4398/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:12 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:0 (0.0 b) TX bytes:816 (816.0 b) vlan1 Link encap:Ethernet HWaddr 08:00:27:DC:43:98 inet addr:192.168.20.1 Bcast:192.168.20.255 Mask:255.255.255.0 inet6 addr: fe80::a00:27ff:fedc:4398/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:12 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:0 (0.0 b) TX bytes:816 (816.0 b)
13.10 ネットワークブリッジデバイスの設定 #Edit source
ネットワークブリッジとは仮想的なリンク層 (レイヤ 2) デバイスで、複数のネットワークセグメント同士を接続して、単一の論理ネットワークにするための仕組みです。ブリッジは仮想的なネットワークスイッチとして振る舞うので、流れるトラフィックを監視してハードウエア MAC アドレスをベースにした動的なフレーム転送を行います。一般的には、物理ネットワークデバイスを複数の仮想マシンで共有するような仮想化環境 (KVM や Xen など) での使用が考えられます。
ネットワークブリッジは YaST を利用してグラフィカルに設定できるほか、手作業で /etc/sysconfig/network/ ディレクトリ内に設定ファイルを作成して設定する方法もあります。
通常は YaST ネットワークデバイスモジュールを利用して設定するのがお勧めです。
手順 13.4: YaST によるブリッジインターフェイスの作成 #
まずは › › を選択します。
を押し、 で を選択したあと、 を押します。
の欄にインターフェイス名 (例:
br0) を入力して を押します。タブでは、まずネットワークブリッジインターフェイスの IP アドレス設定方法を選択 (
DHCPもしくは ) し、後者であれば IP アドレスを設定します。のタブに切り替えます。ここでは、ブリッジに接続する物理ネットワークカード、もしくは VLAN インターフェイスをチェックボックスで選択します。
を押すとネットワーク設定の概要に戻ります。あとは を押すと、設定を保存してネットワークサービスが再起動されます。
13.10.1 手作業によるネットワークブリッジの作成 #Edit source
YaST を使用せずに手作業でネットワークブリッジを作成する場合、ネットワークディレクトリ内に各種の制御パラメータを記述したファイルを作成します。本章の例では、 br0 という名前のブリッジインターフェイスを作成し、 eth0 という物理インターフェイスを追加するまでの手順を説明しています。
手順 13.5: wicked インターフェイス定義によるブリッジの設定 #
まずはネットワークブリッジデバイスの設定ファイルとして、新しい設定プロファイル
/etc/sysconfig/network/ifcfg-br0を作成します:STARTMODE='auto' BOOTPROTO='static' IPADDR='ブリッジに割り当てる_IP_アドレス' BRIDGE='yes' BRIDGE_PORTS='eth0' BRIDGE_STP='off'
また、ブリッジに追加する物理ネットワークインターフェイスの設定も修正します。具体的には、 IP アドレスの設定があれば削除するほか、アドレスの自動取得の設定があれば、これを無効化して純粋な物理ポートとして動作するように設定します:
STARTMODE='auto' BOOTPROTO='none'
固定 IP の設定を行う場合、必要であればデフォルトゲートウエイも明示的に設定します。デフォルトゲートウエイは
/etc/sysconfig/network/ifroute-br0という別のファイルに記述します:default デフォルトゲートウエイの_IP_アドレス - br0

警告: ルータ設定の競合について
デフォルトゲートウエイを設定するにあたっては、あらかじめ物理インターフェイス (例:
ifroute-eth0) 側で設定していないかどうかをご確認ください。物理インターフェイス側で設定してしまうと、カーネル内でルーティング競合フラグが設定され、期待通りに動作しなくなってしまいます。あとはネットワークの設定を再読み込みして、変更内容を反映させます:
>sudosystemctl restart network
13.11 Open vSwitch を利用したソフトウエア定義型ネットワーク #Edit source
ソフトウエア定義型ネットワーク (Software-Defined Networking; SDN) とは、トラフィックの送受信を制御するシステム (制御プレーン) と、実際にトラフィックを配送するシステム (データプレーン もしくは 転送プレーン) を分離する仕組みです。これにより、従来は単一で柔軟性に欠けるスイッチを、スイッチ (データプレーン) とコントローラ (制御プレーン) に分割できることになります。また、このモデルを使用すると、コントローラ側ではプログラム的な処理ができるようになりますので、非常に柔軟で構成変更にも素早く対応できる仕組みにすることができます。
Open vSwitch は OpenFlow プロトコルとの互換性がある、分散型仮想マルチレイヤスイッチを実装するソフトウエアです。 OpenFlow では、コントローラアプリケーションに対してスイッチの設定変更を受け付けることができます。また OpenFlow は TCP プロトコル上で動作する仕組みで、様々なハードウエアやソフトウエア内にも実装されています。そのため、単一のコントローラから複数の様々なスイッチを扱うことができるようになります。
13.11.1 Open vSwitch の利点 #Edit source
Open vSwitch でソフトウエア定義型ネットワークを利用すると、特に仮想マシンと併用する場合に様々な利点をもたらします:
ネットワークの状態を簡単に識別できるようになります。
ネットワークと現在の状態を、一方のホストから他方のホストに移動できるようになります。
ネットワーク上での動作は追跡可能であり、外部のソフトウエアから応答することができます。
ネットワークパケット内のタグを適用したり制御したりすることができますので、どのマシンが通信を行っているのかを判別できるほか、他のネットワークとの関係を管理することもできます。タグ付けのルールは設定および移行することができます。
Open vSwitch は GRE (汎用ルーティングカプセル化 (Generic Routing Encapsulation) プロトコルに対応しています。そのため、たとえばプライベートな VM 同士を接続したりすることができるようになります。
Open vSwitch は単独でも利用することができますが、ネットワークハードウエアと併用するように設計されていて、ハードウエアスイッチを制御することもできるようになっています。
13.11.2 Open vSwitch のインストール #Edit source
Open vSwitch と各種補助パッケージをインストールします:
#zypperinstall openvswitch openvswitch-switchOpen vSwitch と KVM ハイパーバイザを併用する場合は、 tunctl もインストールしてください。また、 Open vSwitch と Xen ハイパーバイザを併用する場合は、 openvswitch-kmp-xen もインストールしてください。
Open vSwitch サービスを有効化します:
#systemctlenable openvswitchコンピュータを再起動するか、もしくは
systemctlコマンドで Open vSwitch サービスを即時に起動します:#systemctlstart openvswitchOpen vSwitch が正しく有効化されているかどうかを確認するには、下記のコマンドを実行します:
#systemctlstatus openvswitch
13.11.3 Open vSwitch デーモンとユーティリティの概要 #Edit source
Open vSwitch は複数のコンポーネントから構成されています。カーネルモジュールのほか、様々なユーザスペースコンポーネントが用意されています。カーネルモジュールはデータパスの高速化のために用意されているものですが、最小限の Open vSwitch インストールでは必ずしも必要なものではありません。
13.11.3.1 デーモン #Edit source
Open vSwitch の中枢は 2 つのデーモンから構成されています。 openvswitch サービスを起動すると、それら 2 つを間接的に起動することになります。
メインの Open vSwitch デーモン ( ovs-vswitchd ) は、スイッチの実装を提供するデーモンです。もう 1 つの Open vSwitch データベースデーモン ( ovsdb-server ) は、 Open vSwitch の設定と状態を保存するデータベース機能を提供します。
13.11.3.2 ユーティリティ #Edit source
Open vSwitch には様々な作業を支援するための各種ユーティリティが用意されています。下記のユーティリティ一覧が全てではありませんが、主要なコマンドのみについて説明を記しています。
ovsdb-toolOpen vSwitch のデータベースを作成/アップグレード/整理/問い合わせすることができるユーティリティです。 Open vSwitch データベースでトランザクション処理を行います。
ovs-appctlovs-vswitchdやovsdb-serverデーモンの設定を行います。ovs-dpctl,ovs-dpctl-topデータパスの作成や修正、可視化や削除などを行います。このツールを使用することで、
ovs-vswitchdの設定を行うことができるほか、データパスの管理も行うことができます。そのため、通常は分析目的でのみ使用します。ovs-dpctl-topはtopコマンドのような出力をするユーティリティで、データパスの可視化を行うことができます。ovs-ofctlOpenFlow プロトコルに準拠する任意のスイッチを管理します。
ovs-ofctlは Open vSwitch を取り扱うだけではありません。ovs-vsctl設定データベースに対する高レベルなインターフェイスを提供するユーティリティです。データベースへの問い合わせや、データベースの修正を行うことができます。実際には
ovs-vswitchdの状態の表示や設定などを行うことになります。
13.11.4 Open vSwitch を利用したブリッジの作成 #Edit source
下記の設定例では、 openSUSE Leap の既定のネットワークサービスである Wicked を使用しています。 Wicked についての詳細は、 13.6項 「ネットワーク接続の手動管理」 をお読みください。
Open vSwitch をインストールして起動してある状態から、下記のようにして行います:
お使いの仮想マシンで使用するブリッジを作成するには、まず下記のような内容で設定ファイルを作成します:
STARTMODE='auto'1 BOOTPROTO='dhcp'2 OVS_BRIDGE='yes'3 OVS_BRIDGE_PORT_DEVICE_1='eth0'4
ネットワークサービスの起動時にブリッジを自動作成します。
IP アドレスを設定するためのプロトコルの指定です。
Open vSwitch のブリッジとして使用する設定です。
ブリッジに追加すべきデバイスです。複数のデバイスを追加する場合は、下記の書式で行を追加していってください:
OVS_BRIDGE_PORT_DEVICE_サフィックス='デバイス'
サフィックス には任意の英数字が入ります。ただし、 サフィックス の値は重複させないでください。
/etc/sysconfig/network内に、ifcfg-br0というファイル名で保存します。 br0 の箇所には、任意の名前を指定してかまいません。ただし、ifcfg-の部分は変えないでください。オプション類について、詳しくは
ifcfgのマニュアルページ (man 5 ifcfg) およびifcfg-ovs-bridgeのマニュアルページ (man 5 ifcfg-ovs-bridge) をお読みください。あとはブリッジを起動します:
#wickedifup br0Wicked の処理が完了するとブリッジの名前が表示され、
upという動作中を示すメッセージが表示されます。
13.11.5 KVM による Open vSwitch の直接使用 #Edit source
13.11.4項 「Open vSwitch を利用したブリッジの作成」 に示す手順でブリッジを作成したら、あとは Open vSwitch を使用して KVM や QEMU の仮想マシンのネットワークアクセスを管理します。
Wicked の機能を最大限に生かすため、作成したブリッジの設定を一部変更します。作成した
/etc/sysconfig/network/ifcfg-br0ファイルを開いて、下記のような行を追加します:OVS_BRIDGE_PORT_DEVICE_2='tap0'
また、
BOOTPROTOをnoneに設定します。たとえば下記のようになります:STARTMODE='auto' BOOTPROTO='none' OVS_BRIDGE='yes' OVS_BRIDGE_PORT_DEVICE_1='eth0' OVS_BRIDGE_PORT_DEVICE_2='tap0'
新しいインターフェイス tap0 は、次の手順で設定を行います。
tap0 デバイスに対する設定ファイルを追加します:
STARTMODE='auto' BOOTPROTO='none' TUNNEL='tap'
上記の内容を記述したファイルを、
/etc/sysconfig/networkディレクトリ内のifcfg-tap0というファイル名に保存します。
ヒント: 他のユーザからの TAP デバイスへのアクセス許可
root以外のユーザで起動した仮想マシンから、 TAP デバイスを使用できるようにするには、下記のような行を追加します:TUNNEL_SET_OWNER=ユーザ名
グループ全体に対してアクセスを許可するには、下記のような行を追加します:
TUNNEL_SET_GROUP=グループ名
最後に、
OVS_BRIDGE_PORT_DEVICEの最初の行に設定したデバイスに対する設定を開きます。今回の例ではeth0になります。/etc/sysconfig/network/ifcfg-eth0ファイルを開いて、下記のオプションを設定します:STARTMODE='auto' BOOTPROTO='none'
ファイルが存在していない場合は、新しく作成してください。
あとは Wicked を利用してブリッジインターフェイスを再起動します:
#wickedifreload br0これにより、新しく設定したブリッジポートデバイスについても、再読み込みが行われます。
仮想マシンを起動するには、たとえば下記のように実行します:
#qemu-kvm\ -drive file=ディスクイメージのパス1 \ -m 512 -net nic,vlan=0,macaddr=00:11:22:EE:EE:EE \ -net tap,ifname=tap0,script=no,downscript=no2KVM/QEMU での使用方法について、詳しくは パートV「QEMU を利用した仮想マシンの管理」 をお読みください。
13.11.6 libvirt での Open vSwitch の使用 #Edit source
13.11.4項 「Open vSwitch を利用したブリッジの作成」 に示す手順でブリッジを作成したら、 libvirt で管理されている既存の仮想マシンをブリッジに追加することができるようになります。 libvirt には Open vSwitch ブリッジのサポートが既に含まれているため、 13.11.4項 「Open vSwitch を利用したブリッジの作成」 でブリッジを作成すれば、あとは特殊な変更を行うことなくブリッジを使用できるようになります。
設定を行いたい仮想マシンのドメイン XML ファイルを開きます:
#virshedit VM_名VM_名 の欄には、仮想マシンの名前を指定します。これにより、既定のテキストエディタが開きます。
<interface type="...">で始まり、</interface>で終わるネットワークセクションを探します。ネットワークセクション内の下記の箇所を、下記のように変更します:
<interface type='bridge'> <source bridge='br0'/> <virtualport type='openvswitch'/> </interface>

重要:
virsh iface-*と Open vSwitch の 仮想マシンマネージャ との互換性について現時点では、
libvirtでの Open vSwitch の互換性はvirsh iface-*ツールや 仮想マシンマネージャ を介しては開示されていません。これらのツールを使用してしまうと、設定が壊れてしまうことがあります。後は通常通り仮想マシンを起動もしくは再起動します。
libvirt の使用方法についての詳細は、 パートII「libvirt を利用した仮想マシンの管理」 をお読みください。
13.11.7 さらなる情報 #Edit source
SDN に関する詳細は、 https://docs.openvswitch.org/en/latest/#documentation にある Open vSwitch プロジェクト Web サイト内のドキュメンテーションをお読みください。